个性经济时代,MiniMax 语音大模型如何 To C?
文章来源:AI科技评论
作者:王悦

大约一个月前,距离 GPT Store 上线还有两周,一位名为 Kyle Tryon 的国外开发者在个人博客上分享了其基于 ChatGPT Plus 开发的三个 Agent(又称“GPTs”),其中一个 Agent 是关于美国费城旅游出行的个人指南“PhillyGPT”,它能访问当地 SEPTA 公共交通 API,为个人提供费城当地的实时天气、旅游资讯、文艺演出活动、出行路线、公交车站与地标数据、预计抵达时间等等。
具体可访问 PhillyGPT 链接:https://chat.openai.com/g/g-GlYMtkbse-phillygpt
费城个人指南的开发背后,实际是人们对于 GPT 时代 C 端个性消费产品的真正想象。无独有偶,1 月 11 日 OpenAI 正式上线 GPT Store 后,公布 300 万个 GPTs 之余,也将与用户日常消费活动息息相关的徒步路线指南“AllTrails”放在推荐榜单上。与国内对大模型前景颇有微词的情况不同,海外大量的个性化应用开发正如火如荼。
个性经济时代,国内大模型经济的发展,实则要改变旧的解题思路。
在国内一众大模型厂商中,MiniMax 就是一家坚持产品创新、追求个性应用的“少数者”。从这一初衷出发,自去年 3 月初亮相起,当大多数团队还处于语言大模型起步阶段时,MiniMax 就以多模态大模型的定位在拥挤的赛道中出类拔萃,估值突飞猛进,成为国内估值最高的大模型厂商之一。
尤为值得注意的是,MiniMax 也是极少数下注语音大模型的团队之一。
区别于文本、图像,语音大模型的研发由于方向小众,社区数据生态并不繁荣,难以获得大量的高质量数据进行模型训练。但在社交、互娱、教育等具有大量个人用户的场景中,声音又往往是许多 To C 与 B2B2C 产品的重要构成,是大模型商业化的兵家必争之地。
近日,MiniMax 也推出了新一代语音大模型,在多项性能指标上超越了传统的语音技术。
语音模型的能力在 MiniMax 自家产品星野中有广泛运用。在近期星野 APP 内发起的 AI 挑战赛中 , MiniMax 语音模型的能力得到充分展示。不仅能语音合成得很自然,还能模拟真人 rap,花样百出,逼近真人 rapper 水准。
(有想在星野 AI 战赛中跟 AI battle rap 的朋友可点击:https://m.xingyeai.com/share/chat?npc_id=64236&share_user_id=54072629321819 进行体验):
据 AI 科技评论了解,MiniMax 最新语音大模型基于长达数百万小时的高质量音频数据进行训练,效果不输 ElevenLabs 和 OpenAI。
同时,MiniMax 也在积极推进语音能力的落地应用,在 To B 侧面打造了开放平台,不断迭代 B 端用户所需要语音能力,在 To C 侧面上线了 AI 语音对话产品「海螺问问」,仅需 6 秒音频即可进行音色复刻。
GPT 时代,MiniMax 的大模型经济打破了单一文本的局限,从“声”出发,定义了个性化应用的新内涵。
1、每个硅基用户都能有自己的声音
AIGC 时代,语音生成的需求实际并不亚于文本与图像。
从 AI 落地的角度来看,大语言模型能够预测出文字序列,是 AIGC 产品工程化的第一步,但在实际应用中,单一的文字呈现效果往往不佳,声音的表现力能为文字内容的情感色彩、个性表达提供有力加持。
以 AI 视频生成为例。在用 AI 技术生成短视频的场景中,“出戏”是用户体验减分的主要短板,而声音则往往是用户出戏的“罪魁祸首”。在 AIGC 产品的应用中,人物音色的还原度、语流语调的流畅度、说话停顿的自然度是语音合成技术的主要挑战,且必须“打包”解决,不能顾此失彼,任一短板都会降低用户的产品体验。
不同场景对语音合成效果的要求也不同。例如,数字人直播带货要求主播与观众的语音互动时效性高、延时性低,复刻有声书需要快速批量生成多角色的音色和语音内容,教育教学场景要求达到对一些特殊字词和生僻字的精准发音。
因此,在传统语音合成技术的基础上,面向用户提供高品质、个性化的语音体验与服务,成为语音生成的下一道难题。
过去,市面上的语音合成技术痛点明显:
- 机械感较强,原因是牺牲部分人声的自然度,声音无法传递出情感;
- 音色较单一,以至于无法提供多种音色供用户选择,也就不能满足不同场景的多样化需求;
- 成本高且效率低下,需要专业的设备且耗时较长。
为了解决这一系列痛点,国内外不少头部大厂也进行过相关探索。
谷歌的多模态大模型 Gemini 尝试对当下流行的文本、图像与语音三种模态的输入内容进行无缝理解和推理,但在实际应用中,Gemini 的文本、视觉、音频被认为是一种“僵硬的拼接状态”。更多关于海内外大模型厂商的信息欢迎添加作者:s1060788086 来聊。
初创企业 ElevenLabs 的语音合成效果惊艳,但更适合英文文本,中文语音合成能力稍逊。
还有诸如 Tortoise 和 Bark 的开源 TTS 模型也积累了一定量的用户,但根据使用反馈,Tortoise 生成速度慢,Bark音质参差,目前较难商用。
与同行争相竞技,MiniMax 也在不断迭代其自研的语音大模型,最新语音大模型使 MiniMax 成为国内第一个开放多角色配音商用接口的大模型公司。
依托新一代大模型能力,MiniMax 语音大模型能够根据上下文智能预测文本的情绪、语调等信息,并生成超自然、高保真、个性化的语音,以满足不同用户的个性化需求。
相较于传统语音合成技术,MiniMax 的语音大模型以更精准、快速的方式,在音质、断句气口、韵律节奏等方面达到以“AI”乱真的合成新高度。
通过结合标点符号以及上下文语境,MiniMax 语音大模型能全方位解读文字背后隐藏的情感、语气,甚至是笑声,都能把握得恰如其分。
在一些特殊语境下,它还能展示出极富戏剧性的声音张力,比如,当说话者被朋友的笑话逗得捧腹大笑时,它也能配合上这种夸张的情绪,同时开怀大笑。
除了超自然的 AI 语音生成效果外,MiniMax 语音大模型的另一个亮点是多样化、高延展——它能够精确捕捉到数千种音色的独特特征,并自由组合,轻松创造出无限的声音变化、情感和风格。这一优势能够灵活地满足社交、播客、有声书、新闻资讯、教育、数字人等多种场景中。
2、长文本语音生成,API 价格降一半
2023 年下半年开始,大模型行业出现两个短兵相接的战场,一是长文本,二是商业化。前者的竞争同样集中在文本领域,从 32k 到 200k 的竞争均已白热化,语音生成则还是一片蓝海;而后者的商业化则主要体现在价格上。
一位大模型从业者告诉 AI 科技评论,“大模型的技术壁垒在降低,到最后就是拼谁能最先将模型训练与部署的成本降下来。”市场对大模型的需求,不再是 ChatGPT 刚火时的二选一,而是既要高性能的模型质量、又要有行业竞争力的产品服务。
在语音生成领域,MiniMax 的文本-语音接口也经历了快速的迭代:
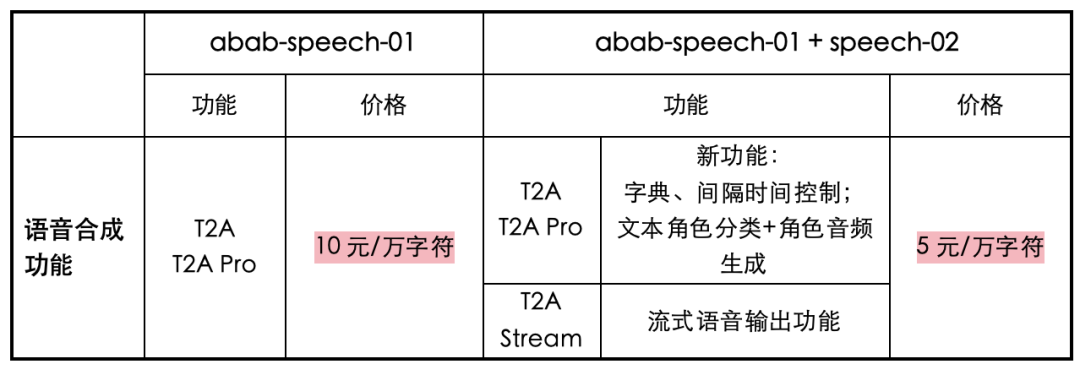
2023 年 9 月 12 日,MiniMax 发布了长文本-语音合成接口 T2A pro,单次语音合成最高可输入 35000 字符,可以调整语调、语速、音量、比特率、采样率等相关参数,主要适用于长文本有声化。
2023 年 11 月 15 日,MiniMax 异步长文本接口 T2A large 上线,支持用户每次上传文本篇幅长达 1000 万字符。
2023 年 11 月 17 日,MiniMax 发布语音大模型 abab-speech-01,其韵律节奏、情感表现、风格多样性、中英混、多语言等能力等整体效果都得到了明显提升。
模型性能提升的同时,MiniMax 也将 API 的价格打了下来:据官方消息,近日 MiniMax 的三个文本-语音接口 T2A pro、T2A、T2A Stream 的价格都已下调为原有价格的一半,从 10 元/万字符降至 5 元/万字符。
基于其自研多模态大模型底座,MiniMax 语音大模型在语音助手、资讯播报、IP 复刻、CV 配音等领域也做了布局。

MiniMax语音大模型产品架构
为了精进模型能力以满足用户对语音的高优需求,2024 年 1 月, Mini Max 开放平台在原有接口能力的基础上新增了以下产品功能:
- 新增三个 API 接口,分别是多角色音频生成API、文本角色分类 API 和快速复刻 API,主要适用于自主批量生成、克隆多角色音频的场景;
- 增加 T2A Stream (流式语音输出)能力,减少用户生成语音的等待时间,实现语音生成与输出同步;
- 增加多语种能力、字典功能、间隔时长控制功能,满足用户丰富的定制化需求。
具体来说,文本角色分类 API 可以快速分辨出不同角色对应的不同对话,角色音频生成 API 可实现多角色区分、多角色播报,快速复刻 API 可以让用户线上快速完成音色复刻。三个 API 结合使用,提供了一整套基于文本的角色声音生产方案——更高效的角色划分,多角色的语音生成,全自助的音色复刻。
MiniMax 告诉 AI 科技评论,该开放平台新增的 3 个 API 接口是为了较好应对篇幅较大的文本内容。
在长文本的语音生成上,过去的一贯做法是用人工标注每段对话的角色归属,再由语音模型生成虚拟声音,缺点是费时费力。而 MiniMax 的语音大模型开放平台使用接口调用,能够更高效地帮助用户生成多角色声音。
以有声书的制作为例。MiniMax 语音开放平台的三个 API 功能接口结合,能省略人工划分文本角色的步骤,自动理解文本、划分角色、为不同角色创造不同声音。联合起点打造有声读物的 AI 新音色"说书先生"与"狐狸小姐",即通过三个接口在线上自主完成高质的声音复刻。这样既能保证人物音色的一致性,又能高效、快捷地对多角色进行配音。
T2A Stream (流式语音输出)能够以 500 字符的输入处理能力迅速响应。针对需要即时反馈的情景,在互动形式的对话中实时生成语音,用户无需等待即可获得语音回复。
同时,T2A Streaming 有混音功能和字符检查功能保障输出内容质量,并提供语调、语速、音量等参数供用户随时调节。它还支持多种音频格式(MP3、 WAV、PCM等)和返回参数(音频时长、大小等),开发者能够依据特定应用的需求来定制化语音服务。
在满足用户定制化需求方面,MiniMax 的语音大模型也升级了三项新功能:
一是多语种能力,使中英文混合输出的声音更自然。
多语种混杂的文本是语音生成的一大难点,频繁的语言切换会导致发音不自然。MiniMax 的语音模型提高了多语言处理能力,在外语教学、口语对话等场景中能够为用户提供更真实的语音体验。
例如,输入文本:“你可以说'In winter, the trees are bare and all the leaveshave fallen off. 这样形容就很形象地传达出那种空空荡荡、没有叶子的树木的冬季景象了。
二是字典功能,允许用户自定义文本读音。
语音模型在根据文本生成声音时会出现发音不准确、读音有偏差的情况,尤其是面对含多音字、特殊符号、文字简写、用户自创的文本内容。为提高发音准确度,MiniMax 语音大模型增加了字典功能,允许用户自主定义文本的读音。
例如:"text" (文本) : omg,单田芳的评书可真是模仿得惟妙惟肖啊。
"char_ to pitch" (标注) : ["单田芳/(shan4)(tian2)(fang1)","omg/oh my god"]
通过这一字典功能,“ 单田芳”和“omg”等多音字和缩略语能够在生成的语音中被正确发音。
三是间隔时长控制功能,可以精细地改善停顿节奏。
MiniMax 语音大模型增加了间隔时长控制功能,让开发者自由在文本中添加不同长度的停顿,精细地调整语句之间的间隔时间、改善停顿节奏,生成语音会更符合真实的教学场景。
这一功能更多被运用在教育教学场景中,其中与高途合作打造的 AI 考研数字人“文勇老师”可以通过这一功能更好地进行听课、答疑,使学生获得更流畅的学习体验。
此外,这一间隔时长控制功能也同样让有声书角色或数字人配音更自然,可以有效扭转传统生成语音无停顿的机械感,增加语音的节奏,更加贴近真人的表达习惯。
教学场景中经常会遇到这样的对话:
老师说:小朋友们,大家好!我是你们的数学老师,我给大家出一个小小的挑战。请听题:小明有7个苹果,如果给了小华 3 个苹果,那么小明还剩下多少个苹果呢?给你们 10 秒钟的时间思考,去找出答案吧!< <#10#> 时间到!大家能告诉我答案是什么吗?对了,小明还剩下4个苹果,那么恭喜你,答对了!因为 7 减去 3 等于 4,所以小明还有 4 个苹果。
在这里,使用控制代码<#X#> (其中 X 是一个数字变量, 单位为秒,取值范围从 0.01 到 99.99 秒)添加间隔标识,就可以在文本中加入用户想要的语音停顿时长。
3、海螺问问 To C,语音拉近人与 AI 的距离
自创立以来,MiniMax 就以 To C 产品形态创新闻名于世。
据 MiniMax 透露,他们在商业化上用 To B 与 To C 两条腿同时走路;而在投资人与市场的眼中,其 C 端产品的创新在国内一众大模型厂商中一骑绝尘,从 Glow 到星野,MiniMax 的 C 端产品一直为人瞩目。
To C 层面,MiniMax 的语音大模型也发挥了独特的优势,这首先体现在其对话产品海螺问问上。

在这款以大语言模型技术为基础的语音对话产品中,MiniMax 自研语音大模型的加持让海螺问问在同类产品中脱颖而出。AI 科技评论一手评测后,最为其超自然、高保真的语音效果所惊讶。单从听感上来讲,海螺问问输出的问答声音难以区分是真人发声还是其语音大模型合成。
例如,在被问到「周末去哪玩?」时,海螺问问输出的语音条就像是一个朋友的口吻和身份,轻轻松松地与对方对话、交流、讨论,而不是如传统 AI 合成语音那般机械地、一字一字蹦出来生成的内容。
听到有趣的问题,海螺问问会发笑;遇到不好回答的问题时,海螺问问会沉吟、会停顿,仿佛在“思考”。如果不是向 MiniMax 求证其在海螺问问上接入了语音大模型,用户大概率会以为机器的另一端是真人对答。
为了达到实时对话的效果,海螺问问在低延时上表现突出,无需传统大模型 5 - 10 秒的思考时间,通过 T2A Stream 能力即时输出。除了语音条的交互形式,也可以点击 UI 界面中右下角的电话小图标,开启实时语音通话。
在正式通话前,用户可以自主选择想要 AI 输出的音色。其中,既有「模仿熊二」的卡通风格,也有「心悦」这般具有亲和力的女声,也有「子轩」低沉有磁性的男声,更有「胖橘」这种类似于古装影视剧中的皇室代表性音色。
除了系统预置的几十种不同风格的声音之外,海螺问问还可以创建自己的声音,在较短时间内通过低样本迅速进行语音复刻。只需要根据界面的指令,朗读一段 40 字左右的给定文本,等待几秒,即可听到高还原度的自己的声音。

如此一来,使用海螺问问的每个普通用户都可以轻松实现无限复刻声音的需求。
但其实,语音复刻的能力在当下的市场中往往是需要付费使用的。很多 AIGC 应用层的厂商会将其视作自家兜售的商品之一,使用者需费时费力地录制自己的音频,再花大几千甚至是几万的价格,为逼真的语音复刻效果买单。在此基础上,还需要限制使用的次数、时长、主体,是个妥妥的赚钱生意。
而海螺问问则免费对用户开发声音复刻的功能,不仅不收费,也不对使用的时长和次数进行限制。同时,操作的流程也很简单,只需 6 秒即可获得克隆音频,这无疑降低了人们使用 AI 改变生活、生产的门槛,在很大程度上方便自己使用。
很多用户反馈,会在海螺问问中录入妈妈的声音,这样在向 APP 咨询生活中的问题时,就仿佛妈妈在旁边为自己答疑解惑,在想要搜索菜谱的时候,就像妈妈在教自己做饭;更有人将失去亲人的声音保留在海螺问问中,通过声音缅怀过去。
另外,海螺问问的意义也不止于用户提问、智能体回答,它在更大程度上是一个能够随意交谈的聊天软件。无需像书面表达一样特别在意语句的准确性、规范性等问题,想说什么即说什么,想怎么说就怎么说,海螺问问都能接招,甚至有时候还会引导话题,主动发问。
更值得期待的是,这两天分享声音的功能将要在海螺问问上线。AI 科技评论独家获悉,通过这一功能,用户之间便可以通过类似口令红包的方式,在微信等社交媒体上相互分享自己克隆出来的声音,进一步实现「语音社交」。
让 AI 声音像人一样自然好听动人,MiniMax 语音大模型在海螺问问上的技术突围和一系列尝试,是向消除人与人工智能隔阂迈出的一个大步子。
过去,人工智能赛道对于语音的理解,是提高语音输入、输出的准确率。现在, MiniMax 则不忘把一缕目光放在影响用户体验的语音交互效果上,这反映的是这家“年轻”公司的战略眼光和执行能力。
2024年,MiniMax 打响语音大模型第一枪,或许值得每一个同行业的探索者思考:当下的世界究竟要向什么方向迭代技术?究竟需要怎样的大模型?究竟要做什么样的产品?
- 1USDT市值突破1100亿美元
- 210 张图揭示加密市场现状:BTC 市占率超 52%,一季度稳定币供应量上涨 14%
- 3加密市场情绪研究报告(2024.04.15-04.19):短期下跌需要做好防御措施
- 4AI 代币另一面:多数项目忙于金融利益,而非现实影响
- 5金色早报丨加密货币价值观仍在全球范围内遭受攻击 铭文某种程度算是符文的试验田
- 6牛市如何暴富?关于加密市场的6点思考
- 7本周值得重点参与的3个链游项目:MapleStory Universe、AI ARENA、My Neighbor Alice「GameFi 猎手」
- 8Bitget研究院:Runes协议上线导致BTC网络费用激增,BONK领涨Solana Meme
- 9一周融资速递 | 33家项目获投,已披露融资总额约1.26亿美元(4.15-4.21)
 币安网
币安网 欧易OKX
欧易OKX 火币全球站
火币全球站 抹茶
抹茶 芝麻开门
芝麻开门 库币
库币 Coinbase Pro
Coinbase Pro bitFlyer
bitFlyer BitMEX
BitMEX Bitstamp
Bitstamp BTC
BTC ETH
ETH USDT
USDT BNB
BNB SOL
SOL USDC
USDC XRP
XRP DOGE
DOGE TON
TON ADA
ADA