大语言模型评测是怎么被玩儿烂的?
文章来源:硅星人Pro

上海人工智能研究室(下简称上海 AI Lab)在徐汇区云锦路上有11幢楼。这里有6000张GPU,也是这座城市在人工智能领域的中心。
这是上海想要抓住的一条新的“黄河路”。今年六月的2023世界人工智能大会,这里是其中一个分会场。那时全球有30多款大模型在上海聚拢。现在国内的大模型数量已经超过了200个。
“你看那边,看到那个麦当劳了吗,他前面黑色的那些建筑群,就是上海 AI Lab了。”从前滩太古里的天桥上可以隐约看到那里,高梵大致指了指。

图源:小红书用户@APP
高梵是爱丁堡大学AI方向的研究生,今年即将毕业,在2023年末回到国内。他是当下比较新的一个大模型评测基准CoT Hub的核心构建者之一。CoT Hub这个项目的发起者是符尧,在这之前,符尧另一项瞩目的工作是C-Eval,大模型中文能力上标志性的评测基准。
OpenAI上九天揽月也下五洋捉鳖,一边琢磨着下一代GPT,一边用GPT Store吃用户,Meta对Llama 2可商用的政策(7亿用户以下),又再次打击了国内在Llama 2出现之前就训出来了的大模型们。
高悬的达摩克利斯之剑不止一把,吊足观众胃口,也急迫地为国内大模型玩家设定了生命线。
“外面看气派吧,其实里面内饰挺简陋的。”
高梵说的是上海 AI Lab那十多幢楼,听上去也是目前国内大模型群体性的反差感。
这句话的背景是,在一些知名的大模型评测基准的榜单上,GPT-3.5、Claude-2甚至GPT-4能够落到10名开外,一些名不见经传的名字则在榜单前列轮流坐庄。
“刷榜是我们的一个陋习。”去年11月,元象XVERSE科技创始人姚星直言不讳。
这也是这次我和高梵见面的目的,想向一位靠近C-Eval又设计过评测基准的人请教一下这件事。
首先,这玩意儿到底是怎么测的?
“C-Eval早被刷烂了”
“我的意思是,你们做评测基准,还自己花这个钱来测吗?”
评测分两种,自己测或是提交,“C-Eval嘛,大多数是后者”,高梵说。
包括爱丁堡大学在内,英国一所高校在GPU上的存量大概在200-400张的区间,美国多一些,沙特更多,中国则更少。如果只考虑不做工程优化的那种无脑跑,一张卡一个任务集可能要跑一天,这个计算成本和时间成本都是很高的。所有通常,这些卡和资金有限的学术性评测基准团队,只能是靠着大模型公司拿着论文自己跑测试,然后把评分汇总给评测基准团队。
自己提交,那跑榜单这件事的变量就多了。
“符尧很敏锐,这是件用爱发电的事,但结果是C-Eval被刷惨了”,高梵说。
符尧是高梵在爱丁堡大学的学长。C-Eval开始构建的时候他还不认识付尧,但高梵知道C-Eval做的很早,早到甚至像是Chatgpt出现之前就开始的项目,所以当今年年初大量意在做中文能力评测的评测基准都仍然在做着英文数据集简单粗暴的的翻译工作时,C-Eval第一个从零开始构建了自己的数据集,用大量时间和人工标注把数据集堆上去,然后一下子成了中文大模型中标志性的评测基准。

C-Eval对自己的声明 图源:C-Eval
C-Eval很快成为这一波大模型热潮里最被广泛认可的榜单之一。然后很快,它也是最先被刷烂的榜单。
6月份的C-Eval榜单上,ChatGLM 2超过GPT-4排名第一,第三名是商汤的日日新。
7月,APUS天燕大模型和容联云赤兔大模型紧随排名第二的GPT-4冲进前六。一个月后,C-Eval榜单的榜眼位置换成了一家成立仅两个月的初创公司共生矩阵。又过了一个月,这份榜单上力压GPT-4的国产大模型突然增加到8个。
从10月开始,GPT-4在C-Eval上的平均分掉出前十。
几乎每一个国产大模型的推出,都会从一份亮眼的C-Eval分数开始。几个月前见到智源研究院的林咏华时,她直言几个权威的榜已经被刷的太严重,失去了参考价值,其中提到C-Eval。
百川智能在8月抛弃了C-Eval,因为那时候如果不作弊,百川模型的分数就只有50多分。一个GPT-4只能拿到70分的评测基准,50分对于一家创业不到半年的初创公司来说已经可喜,但这样的“低分”连前10都进不了,在国内模型排名里会排在很后面。“但我们又不愿意作弊”,一位百川智能的内部人士说。
这种“作弊”高分可以用刷题实现,并且大量进入C-Eval榜单前列的大模型都是这么做的。“这几乎已经是公开的秘密”,高梵说。
很早就有人关注到这一点。一篇《Rethinking Benchmark and Contamination for Language Models with Rephrased Samples》的论文里显示出来的迹象是,一些轻微的数据泄露——训练集和测试集之间的数据重叠——就可能导致评估结果的显著提升。
当数据泄露情况发生,大模型会过度适应这些它“背到过”的训练数据。这会让小参数模型表现超过大参数模型,也会让差的模型得分比优秀的模型表现更好,这最终会导致对模型性能的不可靠评估。这种重叠不只发生在词句上,也就是说,把一些题中的原词作原意替换放进去训练,这种数据污染的情况仍然存在。
这会造成一定程度的过拟合,也就是让模型在训练数据上学习到了过多的细节,以至于它开始记忆特定的数据点,而不是学习到数据背后的一般规律或模式。
智源研究院内部的研究表明,这种刷分所造成的过拟合现象,可能会影响模型本身的“智力”。这种担心很可能是正确的。
去年11月,中国人民大学和美国伊利诺伊大学厄巴纳-香槟分校的联合团队曾经选取了当时市面上流行的几个大模型,控制变量的来测试它们刷题后的表现变化。结果是经过泄露数据训练的大语言模型在文本生成和代码合成任务上的表现都有不同程度的下降。
OpenLLaMA-3B和LLaMA-2-7B在XSum任务上的ROUGE-L分数分别从0.19和0.25降低。这种能力衰退哪怕在用Alpaca和CodeAlpaca数据集再次对模型进行指令微调都调不回来。
刷题这件事像是从NLP和CV时代就延续下来的肌肉记忆。最近的一个新模型的发布会现场,创始人出来,聊到刷分,说团队奔着刷分训了一个“应试教育”版本,分数超过GPT-4,技术人员还跟他说——分够吗,不够还能再往上拔点。这位创始人当然是当作玩笑讲的这件事。但等到了模型介绍,第一句话仍然是“模型在各种榜单上SOTA”,他自己也有些哭笑不得。

图源:LessWrong
“那‘做题’这件事,能一条路走到黑吗?”
“如果能设计出那种足够接近ground truth的数据集的话”,高梵说。
但那意味着一个超级大的题库,比C-Eval这样的要大得多。C-Eval里面已经包含了多达超过100个任务,BBH有200多个任务。这也是为什么C-Eval多是大模型公司自己测完提交——能否完整跑下来这样的测试集本来就是一种门槛。
“更何况测试基准的影响因素远不止做题这一件事。”
脆弱的评测
“如果测试不在一种统一标准下进行的话,你会发现这个变量简直是无限多——温度,你的解码策略、Prompt(提示词)等等等等......每个榜单都会有标准的建议实现,但它不一定是你这个模型表现最好的形式。”
高梵举了个例子。
比如做多选题,有的测试方法是把题库的答案变成一串字母排列(A/B/C/D或多选),然后拿着生成的字母序列去和正确的序列相比,看这整个一串答案的正确率。也有直接测“The answer is”后面那个Token的,比如说正确答案是A,你只要测出来是a的概率大于B和C,就算你答对这道题——哪怕它其实并不知道为什么选A。
“光解码策略就有n个方法,而且除了测ABCD的概率,还有测带不带括号的概率——偏好有很多种,这个其实挺复杂的。”
Anthropic的一篇技术论文也在说同样的事。Claude团队表示,对简单的格式变化敏感,例如将选项从 (A) 更改为 (1),或者在选项和答案之间添加额外的空格,这些做法都可能导致评估准确率约有 5% 的浮动。
但退一步讲,如果所有模型都按一个方法测也可以,这是每个测评基准遇到的一样的问题。
这也是为什么HuggingFace这么受到推崇的原因之一,他们有足够的卡,并且提供了一套全自动的模型能力评测框架。这意味着不管模型经过了什么“讨巧”的训练,至少在评测这个环节上他们能够被放在同一个水平线上。
“但HuggingFace上的评测也不是没出过事故吧。”
我记得有这样一起“事故”。当时的背景是,Falcon的分数很高,Llama1-65B在Open LLM Leaderboard(HuggingFace的自动化模型榜单)上MMLU的分数异常的低。最后研究下来原因仅仅是自动化测评框架有一个Bug。这个错误很快被修复了,但仍然在社区里引起了一番讨论。
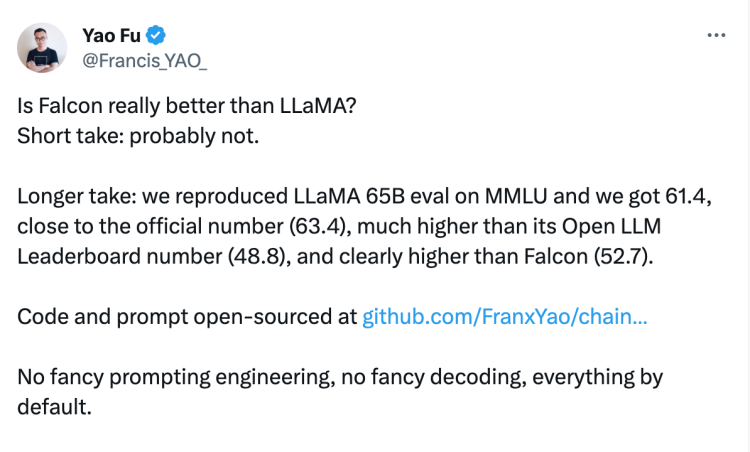
图源:X
CoT Hub本身也是这起事件的主角之一,正是他们发起了对Llama1-65B在MMLU上表现的再次测试。
一个自动化脚本的Bug,导致这个模型在MMLU上的正确率降了20%,也就是刷分成绩掉了20分——要知道GPT-4在MMLU上减掉20分后,连GPT-3.5Turbo都不如。
这个测试事故或许能反映出来测评这件事本身是多么脆弱易碎。
“但总归,这是目前最好的办法,CoT Hub未来也可能朝全自动化的方式更新一版”,高梵说。
“不过,最大的变量其实是Prompt。”风大的很,我们躲进了对面的一家书店。
最大的问题是Prompt
茑屋书店在前滩太古里的这家店是上海的第二家门店,到现在已经开了两年多。时下的畅销书多摆在动线上的黄金位置,现在多了很多“ChatGPT”和“AIGC”的字眼。
最先活跃起来的布道者们已经把新时代扯到嗓子眼了,但对普通人来说又什么都还未来临。
几个星期前,我见到了其中一本畅销书的作者,他对于2024年生成式AI最笃定的预测是——AI网红。听起来靠谱又无聊。如果写书、卖课算是某种程度的布道,赚新时代的头金,模型评测则是另一种,这些榜单像是淘金者从西部回来的第一批承销商。
“这意味着什么,关于刚才说的Prompt?”
“提示词的敏感度是很高的。”高梵说,“什么意思呢,比如Claud的系列模型,我光是Prompt改一改,对评测分数的扰动就会有10%。”
测试时怎么用Prompt有很多“坑”,里面很多是工程问题。比如MMLU——你可以理解成它是一个做多选题的题库,然后你要知道被测的模型做出了怎样的回答。这个答案回收的过程,大部分的评测基准只是做一个字符串的匹配,但这个方式其实很不稳定,考虑到对于测评结果提取位置的精确性上甚至有点“灾难”。
提取字符串这件事的逻辑,人类大脑看来很简单,但这只说明人类大脑的高明罢了。
“如果模型的回答是‘选b’,那‘b’这个字符可以轻松被提取出来。但如果模型的回答是‘不应该选c,应该选b’呢,这时候答案是‘b’、‘c’还是‘b&c’?”
这就需要让模型符合规范的回答,比如在模型的Few-Shot例子中都以“Answer: ”来训练。这样一来,似乎在“Answer: ”字符串后面的就应该是模型想要的回答。但高梵和团队成员的测试结果是,这个方法对GPT家族的模型效果都不错,因为GPT不喜欢乱说话。但是对Claude或者Llama家族模型,可能会产生 “这道题选b是不对的,应该选c” 这样不按常理出牌的回答。
“哪怕你再嘱咐它‘你不要说别的’也没有用,这个时候提取器就会失效——只有GPT-4可以以接近人类的理解能力进行答案提取,但是不会这么去测试,因为成本不可能划得来。”
为了解决模型不乱说话的问题,需要一些Prompt的技巧,而CoT Hub在测试后发现,在Claude优化前和优化后能有10%的扰动。这几乎是贯穿大模型评测这件事的一个不可控的风险。
为了公平起见,在大模型评测时,理论上应该遵循相同的答案提取规则。开源社区是这么做的,为了对所有模型一视同仁,开源社区默认的只有一个提取规则,比如 “Answer: ”。
但这又成了一件矛盾的事,一个评测基准到底该为了保证公平而坚持用相同提取器和提示词的组合来测试所有模型,还是为了度量模型的潜力?
前者由于太多的变量参杂看起来缺乏横向比较的意义。如果是为了后者,Prompt如何挤压出一个大模型的性能上限,需要更多精细的研究。

图源:arXiv
“寻找Prompt的最优解,可以说我们那时候最多的精力都花在这上面。”
这是一个正在越来越被重视的研究方向。平庸的Prompt本身就存在着无法调动出大模型能力上限的可能性,寻找并且验证Prompt的最优解这件事任重道远。
CoT Hub严格来讲现在一共就4个人,但是每个阶段的参与者不一样。一开始符尧和他带的几个本科生开始动手写基础代码,后来几位本科生因为别的事离开,高梵加入。
听高梵的描述,这是个比较松散的项目,每天写个两三小时代码,每周开一次会。按高梵的说法,“反正就零零散散做着”。这个项目从2月发起,到5月成型,在10月上了GitHub,到现在也有超过2000颗星。
每个研究都有它的时代背景。在CoT Hub之前,大部分的大模型评测都是以Zero-Shot和单轮对话的方式来做的,也就是在一次对话动作中提出问题并且得到答案。但这样的简单方法容易被针对性训练,并且在大模型更高级的性能考察上缺乏区分度。
CoT Hub没有做新的数据集,只是把市面上优质的数据集拿来,打磨合适的Prompt,把原先Zero-Shot的方式转换成多轮对话,以及对CoT能力的考察。
任务复杂后,模型的性能进一步分出层次。CoT Hub团队在当时得出的结论是,开源的Llama-65B模型性能已经非常接近code-davinci-002,也就是GPT-3.5的基础模型。但即便如此,开源模型和封闭模型的差距还是很大。而在真正有挑战性的数据集上(比如Big-Bench-Hard),小参数模型与大参数模型的差距十分惊人,而不是像一些文章或者灌水论文中所说,前者可以“以小搏大”的复现大参数模型的性能,甚至直追ChatGPT。
看起来“幻觉”这件事,不仅出现在模型上,也出现在榜单上。但后者何尝不是对人类大脑幻觉的一种映射呢。
最终我们要测的是超越人类的智能,能测么?
一位活在二维世界里,谦卑的平面国居民“正方形”先生某一天遇到了从三维国前来传福音的“球”先生,“球”先生可以轻松的看到“正方形”先生的身体内部,甚至穿过它,就像用手指从上方捅破一张纸。但后者却无法理解这一切。

图源:知乎@李想
这是我对大模型评测这件事最大的疑问:
如果对大模型的期望是奔着AGI而去,那该怎么用人类设计的评价标准来衡量或者描述一种比人类更高级的智能?
高梵提供了一种思路:这件事或许可以理解成,如何找到一种方式帮助人类去监督大模型的表现,并且让这种监督有足够的扩展性。
“比如我们要让一个小学学历的数据标注员能够对模型在MMLU上的表现作出判断,如果这件事成立,那或许就可以拓展到人类极限去看超越人类极限的测试结果”,高梵说。
他给我看了一个很有趣的工作——准确的说是一个的Demo——关于如何让一个非程序员在有了一些特别的的工具后能够像程序员一样来标记数据集。
在OpenAI在12月发出的一篇关于超级对齐(Superalignment)的论文里,展示了一种用GPT-2去监督GPT-4的方法,这与前面的例子一样都是“弱”监督“强”的逻辑。
这件事属于可监督拓展(scalable oversight)的范畴——去年7月OpenAI首次公布超级对齐计划时有所提及——关于如何监督一个在特定领域表现超出人类的系统,并且寻找它能够大规模scale上去的可能性。可监督拓展是对齐领域的一个分支,有一些研究者在推进这方面的研究,其中有一位是NYU的教授,“他同时在Anthropic兼任做指导”。
现在领导着OpenAI“超级对齐”部门的则是伊尔亚,但在一个月前OpenAI内部兵变之后处境尴尬,也很少在X上更新动态。
他“消失”前最后一个工作,就是OpenAI那篇关于“超级对齐”的论文。论文里提到了另一种大模型超越人类的探索:辩论。
高梵最关注这个。
“可是——辩论?”
“人类有两条线,一条是形式语言上的,也就是逻辑学范畴,这条线延伸到现在就是计算机语言。与之平行的还有另一条非形式语言的线——那些关于语用学、语义学、修辞学的东西——发展到现在就和辩论的艺术有关,比如法学。”
“辩论能力以及说服能力,这是目前在AI智识中还未被定义清楚的能力。但既然推理能力能够被定义清楚,同层次的辩论理论上也是应该能迁移到语言模型上的,只是现在的研究还太浅。”
我记得GPT-4刚出的那两个月里曾经冒出来过一篇论文,论文作者让大语言模型扮演卖气球这个任务中的买卖双方,再加一个大模型“评论家”为买卖双方提供反馈意见,气球价格从20美元起跳,来看最后会被砍刀什么价格。
从实验内容上,这在考研大模型的辩论能力,从评论家角度,这个实验跟用GPT-2监督GPT-4有点像,是可监督扩展中很有代表性的路线。这篇论文的作者也是符尧,这位C-Eval的“始作俑者”,下一站是谷歌的Gemini。
这些模型基准遇到的问题和设计者们在尝试的思路,甚至“始作俑者”的工作选择,都在说明一件事:大模型最终不会停留在这些多选题和榜单上。
而真正在做大模型的公司也早已经有了自己的方法。外部公开的评测基准现在更多的角色是一种面向公众的宣传手段(甚至连ToVC都算不上),而在大模型公司内部,他们往往有一套更有针对性的评测基准。
一位在当下非常受瞩目的某大模型公司做产品负责人的朋友说,这套内部的评测基准,需要非常漫长的调试才能成型,它实际上是一家大模型公司最核心的资产,为自己模型的训练和迭代提供方向。
“评测基准从一开始的滞后,到后来成为一种被利用的工具而逐渐泡沫化,现在最泡沫的时期也差不多要过去了”,高梵说。
“最终,用户会用脚投票的”。
- 1USDT市值突破1100亿美元
- 210 张图揭示加密市场现状:BTC 市占率超 52%,一季度稳定币供应量上涨 14%
- 3加密市场情绪研究报告(2024.04.15-04.19):短期下跌需要做好防御措施
- 4AI 代币另一面:多数项目忙于金融利益,而非现实影响
- 5金色早报丨加密货币价值观仍在全球范围内遭受攻击 铭文某种程度算是符文的试验田
- 6牛市如何暴富?关于加密市场的6点思考
- 7Bitget研究院:Runes协议上线导致BTC网络费用激增,BONK领涨Solana Meme
- 8本周值得重点参与的3个链游项目:MapleStory Universe、AI ARENA、My Neighbor Alice「GameFi 猎手」
- 9一周融资速递 | 33家项目获投,已披露融资总额约1.26亿美元(4.15-4.21)
 币安网
币安网 欧易OKX
欧易OKX 火币全球站
火币全球站 抹茶
抹茶 芝麻开门
芝麻开门 库币
库币 Coinbase Pro
Coinbase Pro bitFlyer
bitFlyer BitMEX
BitMEX Bitstamp
Bitstamp BTC
BTC ETH
ETH USDT
USDT BNB
BNB SOL
SOL USDC
USDC XRP
XRP DOGE
DOGE TON
TON ADA
ADA