文字序顺不响影GPT-4阅读理解,别的大模型都不行
文章来源:量子位

图片来源:由无界 AI生成
研表究明,汉字序顺并不一定影响阅读(对于英文来说,则是每一个单词中的字母顺序)。
现在,日本东京大学的一项实验发现,这个“定理”居然也适合GPT-4。
比如面对这样一段“鬼画符”,几乎里面每一个单词的每一个字母都被打乱:
oJn amRh wno het 2023 Meatsrs ermtnoTuna no duySan taatgsuAu ntaaNloi Gflo bClu, gnelcinhi ish ifsrt nereg ecatkjnad ncedos raecer jroam。
但GPT-4居然完美地恢复出了原始句子(红框部分):

原来是一个叫做Jon Rahm的人赢得了2023年美国大师赛(高尔夫)的故事。
并且,如果你直接就这段乱码对GPT-4进行提问,它也能先理解再给出正确答案,一点儿也不影响阅读:

对此,研究人员感到非常吃惊:
按理说乱码单词会对模型的tokenization处理造成严重干扰,GPT-4居然和人类一样不受影响,这有点违反直觉啊。

值得一提的是,这项实验也测试了其他大模型,但它们全都挑战失败——有且仅有GPT-4成功。
具体怎么说?
文字顺序不影响GPT-4阅读
为了测试大模型抗文字错乱干扰的能力,作者构建了一个专门的测试基准:Scrambled Bench。
它共包含两类任务:
一是加扰句子恢复(ScrRec),即测试大模型恢复乱序句子的能力。
它的量化指标包括一个叫做恢复率(RR)的东西,可以简单理解为大模型恢复单词的比例。
二是加扰问答(ScrQA),测量大模型在上下文材料中的单词被打乱时正确理解并回答问题的能力。
由于每个模型本身的能力并不相同,我们不好直接用准确性来评估这一项任务,因此作者在此采用了一个叫做相对性能增益(RPG)的量化指标。
具体测试素材则选自三个数据库:
一个是RealtimeQA,它每周公布当前LLM不太可能知道的最新消息;
第二个是DREAM(Sun et al.,2019),一个基于对话的多项选择阅读综合数据集;
最后是AQuARAT,一个需要多步推理才能解决的数学问题数据集。
对于每个数据集,作者从中挑出题目,并进行不同程度和类型的干扰,包括:
1、随机加扰(RS),即对每一个句子,随机选择一定比例(20%、50%、100%)的单词,对这些单词中的所有字母进行打乱(数字不变)。
2、保持每个单词的第一个字母不变,剩下的随意排列(KF)。
3、保持每个单词的首字母和最后一个字母不变,剩下的随机打乱(KFL)。
参与测试的模型有很多,文章正文主要报告了以下几个:
text-davinci-003、GPT-3.5-turbo、GPT-4、Falcon-180b和Llama-2-70b。
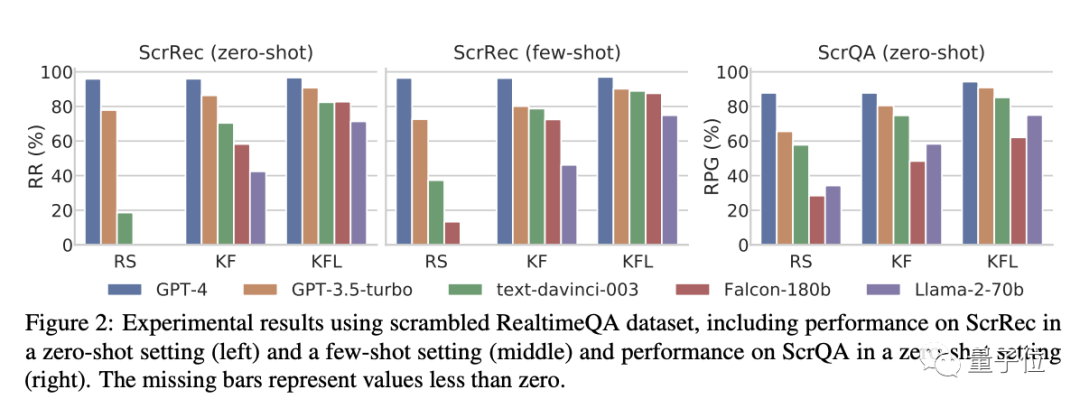
首先来看不同干扰类型的影响。
如下图所示:
在KFL设置中(即首尾字母不变),不管是加扰句子恢复还是加扰问答任务,模型之间的性能差距都不大。
然而,随着干扰难度越来越高(变为KF和RS后),模型的性能都迎来显著下降——除了GPT-4。
具体而言,在加扰句子恢复(ScrRec)任务中,GPT-4的恢复率始终高于95%,在加扰问答(ScrQA)任务中,GPT-4的相对准确性也都始终维在85%-90%左右。
相比之下,其他模型有的都掉到了不足20%。
其次是不同加扰率的影响。
如下图所示,可以看到,在加扰句子恢复(ScrRec)任务中,随着一个句子中被干扰的单词数量越来越多,直至100%之后,只有GPT-3.5-turbo和GPT-4的性能没有显著变化,当然,GPT-4还是比GPT-3.5优先了很大一截。
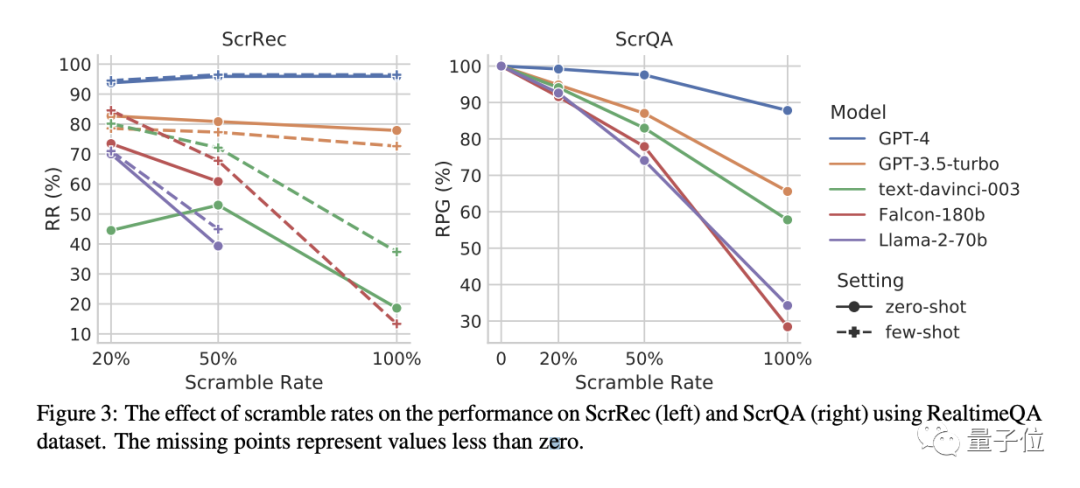
而在加扰问答(ScrQA)任务中,随着句子中被打乱的单词数量越来越多,所有模型性能都出现了都显著下降,且差距越来越大。
但在其中,GPT-4还能以87.8%的成绩保持遥遥领先,并且下降幅度也是最轻微的。
所以简单总结来说就是:
大多数模型都可以处理一定比例的干扰文本,但到极端程度时(比如单词全部打乱),就只有GPT-4表现最好,只有GPT-4面对完全混乱的词序,几乎不怎么被影响。
GPT-4还擅长分词
在文章最后,作者指出:
除了打乱单词字母顺序之外,还可以研究插入字母、替换字母等情况的影响。
唯一的问题是,由于GPT-4为闭源,大家也不好调查为什么GPT-4可以不被词序影响。
有网友发现,除了本文所证明的情况,GPT-4也非常擅长将下面这一段完全连起来的英文:
UNDERNEATHTHEGAZEOFORIONSBELTWHERETHESEAOFTRA
NQUILITYMEETSTHEEDGEOFTWILIGHTLIESAHIDDENTROV
EOFWISDOMFORGOTTENBYMANYCOVETEDBYTHOSEINTHEKN
OWITHOLDSTHEKEYSTOUNTOLDPOWER
正确分隔开来:
Underneath the gaze of Orion’s belt, where the Sea of Tranquility meets the edge of twilight, lies a hidden trove of wisdom, forgotten by many, coveted by those in the know. It holds the keys to untold power.
按理来说,这种分词操作是一件很麻烦的事儿,通常需要动态编程等操作。
GPT-4表现出来的能力再次让这位网友感到惊讶。
他还把这段内容放进了OpenA官方的tokenizer工具,发现GPT-4看到的token其实是这样的:
UNDER NE AT HT HE GA Z EOF OR ION SB EL TW HER ET HE SEA OF TRA
这里面除了“UNDER”、“SEA”和“OF”之外,几乎剩下的所有token都看起来“毫无逻辑”,这更加使人费解了。

对此,大伙是怎么看的呢?
参考链接:
[1]https://arxiv.org/abs/2311.18805
[2]https://news.ycombinator.com/item?id=38506140
- 1USDT市值突破1100亿美元
- 210 张图揭示加密市场现状:BTC 市占率超 52%,一季度稳定币供应量上涨 14%
- 3加密市场情绪研究报告(2024.04.15-04.19):短期下跌需要做好防御措施
- 4AI 代币另一面:多数项目忙于金融利益,而非现实影响
- 5金色早报丨加密货币价值观仍在全球范围内遭受攻击 铭文某种程度算是符文的试验田
- 6Bitget研究院:Runes协议上线导致BTC网络费用激增,BONK领涨Solana Meme
- 7牛市如何暴富?关于加密市场的6点思考
- 8本周值得重点参与的3个链游项目:MapleStory Universe、AI ARENA、My Neighbor Alice「GameFi 猎手」
- 9一周融资速递 | 33家项目获投,已披露融资总额约1.26亿美元(4.15-4.21)
 币安网
币安网 欧易OKX
欧易OKX 火币全球站
火币全球站 抹茶
抹茶 芝麻开门
芝麻开门 库币
库币 Coinbase Pro
Coinbase Pro bitFlyer
bitFlyer BitMEX
BitMEX Bitstamp
Bitstamp BTC
BTC ETH
ETH USDT
USDT BNB
BNB SOL
SOL USDC
USDC XRP
XRP DOGE
DOGE TON
TON ADA
ADA