只凭CPU/GPU性能换机的时代,过去了
原文来源:硅星人

图片来源:由无界 AI生成
上周,一款全新“小“设备点燃了全球科技界的热情。它就是由OpenAI CEO Sam Altman投资的、人类历史上第一款真正的AI硬件——AI Pin。

AI Pin使用时直接别在胸前 自:Humane官方
这款别在胸前、被众多媒体冠以“AI时代iPhone”的硬件,在设计突出一个“激进”,直接砍掉了过往中枢移动设备肯定有的显示屏,还要独立于智能手机运行。

官方演示中AI Pin可以直接计算手中的杏仁有多少克蛋白质 自:Humane官方
在应用层面,由GPT4驱动的AI助手既是系统,也是唯一的App。用户的语音命令就是最主要的操控方式。剩下的激光投射和手势识别,仅仅是作为整个交互系统的补充存在,以非常简单的界面和操控为用户提供包括信息、天气、时间、日期、导航等内容。
知名开发者Steven Tey表示AI Pin让他想起了当年iPhone的发布
这种对于整个移动互联网时代交互逻辑的颠覆,让AI Pin获得了很多极客用户的喜爱。
而大多数普通用户的想法,其实是“希望将这种交互和能力,内嵌到智能手机之中”,让智能手机再次获得升级。
显而易见,随着大模型的各种能力逐步落地,消费者即将进入一个考虑自己的移动设备能否流畅运行AI能力,而不是只考虑CPU、GPU绝对性能的时代。而这,必将带来新的挑战和机会。
移动端普及AI大模型,有哪些挑战?
首要的,是来自于AI大模型提出的全新计算能力需求。
与手机和笔记本之前面对各种系统、软件负载不同,大模型相比过往的AI应用,在神经规模大小、计算量、存储空间、读写速度的需求上,有了数十倍的增长。
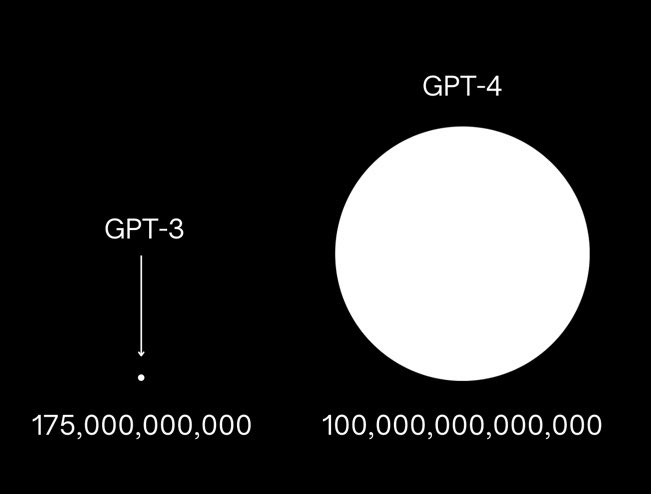
GPT-3和GPT-4的参数规模对比 自:medium
以OpenAI最新的GPT-4模型为例,据行业内传闻就有高达1.8万亿个参数,而其2018年发布的GPT-1,仅有1.1亿个参数。规模相差10000倍。
即便是移动端大模型应用阶段对模型进行瘦身,但实际应用的推理模型参数量也将高达70亿-100亿个参数。再靠过往的移动端升级CPU和GPU硬件规格的方法,肯定无法满足数倍乃至数十倍增长的AI计算需求。
解决新增需求的方法只有两个,要么联网,用网络把计算过程“转移”到云端。要么想办法提升计算力,在本地直接计算出结果。
开篇介绍的AI Pin,产品中就打包整合了美国运营商的联网服务,其每月24美元的月租,除了掏钱买OpenAI的服务能力之外,也有移动网络的花费。
这套看似“简洁”的处理方法,同样存在着不少的疑问。
首先是最危险的隐私问题,将个人的数据、个人绝大多数的生活点滴,甚至是一些极其私人的信息全部任由AI Pin这样的硬件上传,会导致数据安全隐患。
退一步说,把所有AI计算需求放在云端,由本地上传数据再下载数据的方式,网络的质量将极大影响最终使用的体验。尤其是在移动网络覆盖本就不如中国好的海外,卡顿乃至无响应大概率都会出现。
成本上的挑战也同样值得关注,一次性购买的本地计算能力,虽然比连续订购的云上算力先期投入大,但全生命周期往往要划算得多。就以AI Pin为例,699美元的起售价,每个月还要付24美元的租金,实属不便宜。
整合以上三点,不难得到一个结论:AI大模型在移动端实现本地化,才是最优解。
相应地,移动设备行业需要进行一次从底层硬件到顶层生态的全面升级。
抢跑AI时代的高通
回望整个移动端市场,有能力推动这场全面升级的玩家,已经参与其中付出努力的更是少数,高通恰恰是其中一个。
在年初的MWC2023上,高通就展示了生成式AI模型——Stable Diffusion在第二代骁龙8赋能的智能手机上的运行。Stable Diffusion模型的规模为10亿参数,第二代骁龙8可以在15秒内执行20步推理,把文字提示生成一张图像。

第三代骁龙8移动平台亮点一览
而在高通最近发布的全新旗舰移动平台第三代骁龙8上,高通AI引擎的核心Hexagon NPU再次升级,整体性能再度提升了98%,能效也提升了40%。
在更细分的性能纬度,最新的Hexagon NPU通过集成更强的高通传感器中枢,包括2个始终感应ISP、1个DPS、2个micro NPU,增加30%的内存以及对INT4计算模式的支持,让其AI运行性能最大提升3.5倍。
直观上的结果是,第三代骁龙8能够运行高达100亿参数的生成式AI模型,并以20 tokens/s的速度运行大语言模型。并且这不仅仅只是支持的数字而已,而且是已经可以实现的能力。
如此强大的性能,让第三代骁龙8已经能够在本地运行很多AI大模型相关的应用。
荣耀手机CEO赵明就在骁龙峰会上演示了手机上的生成式AI用例,能够支持在手机上完成主题视频的创作。手机系统可以自己在本地媒体库中检索出具有相同主题的图片和视频,然后让AI大模型进行视频编辑。
用户后期可以通过与AI对话更改背景音乐和模板,这一整个过程,未来将完全在本地进行,丝毫不用担心私人照片视频数据在上传到云端之后不小心泄露。
而在小米14系列上,已经适配的WPS不仅持输入主题一键生成PPT演示文稿,还可以识别带有文字的图片和文章,实现“一目十行”扫描阅读,提炼出重点,用户可以按照自己最想要知道的问题向AI直接提问。

小米14上的WPS功能演示
针对论文、合同、课件等文件,WPS AI通过扫描识别进行翻译、概括、查询定位等,可帮助用户进行全文理解分析和总结,同时提供文档溯源功能,确保准确性、真实性。
在强大的第三代骁龙8移动平台之外,高通在此次峰会上还推出了迄今为止其面向PC打造的最强计算处理器:骁龙X Elite。
其中在CPU部分,高通祭出了兼容ARM指令集的前提下完全重构的Oryon CPU,官方表示其单核性能领先苹果M2 Max约14%,且功耗减少30%;同时CPU单线程性能超过了专门为高性能游戏终端而设计的i9-13980HX,并且在相同性能水平下功耗减少70%。
GPU部分的Adreno GPU性能也有所提升,达到4.6万亿次浮点运算(TFLOPS),同时支持4K@120Hz HDR10屏幕,并可以扩展三个UHD或者两个5K外接显示器。
最为亮眼的当属NPU部分,相比手机移动平台,X Elite的异构算力进一步提升,达到75TOPS,其中Hexagon NPU支持45TOPS算力。出色的性能让其已经可以实现在本地运行130亿参数模型;运行70亿参数大语言模型可以每秒生成30个token。
在骁龙峰会的现场,知名视频剪辑软件达芬奇的制作方Blackmagic Design也给出了骁龙X Elite在AI方面的使用效果:对于支持AI的计算密集型Magic Mask,骁龙X Elite比采用集成GPU的高端十二核Windows处理器快1.7倍;Magic Mask在集成NPU上运行,比在相同的12核处理器上运行快3倍。

骁龙X Elite芯片亮点一览
手机端和笔记本端出色的运行结果背后,除了高通强大的芯片性能之外,也有着高通整体AI软件栈的功劳。例如这一次峰会上,高通就宣布了增加对ONNX Runtime快速访问骁龙芯片、对Microsoft计算驱动程序模型(MCDM)的支持。
前者是一个是微软推出的推理框架,支持多种运行后端,开发者在制作相应的推理应用时,可以更加高效;至于对MCDM的支持,未来高通NPU在Windows系统中的调用将会更加高效直接。
高通在生态方面的这些努力,在帮助终端厂商伙伴打造出色产品的同时,也吸引了越来越多独立软件开发商(ISV)和开发者加入到高通的生态中来,推动AI大模型应用在高通平台上的落地和推广。
仍在加速的高通
从启动首个AI研究项目至今,高通在AI领域已经深耕十余年。多年来在移动平台中的技术积累,以及对AI能力的不断探索,最终在如今AI大模型落地的瞬间爆发出来。
按照半导体行业芯片3年左右的开发周期推算,这次新登场的、性能极为出色的第三代骁龙8移动平台和骁龙X Elite,早在2020年左右就已经进入了开发程序,可见高通对于移动设备、人工智能行业的深度理解与把握。
这种对于最前沿技术的追求、对于为用户带来最极致体验的初心,驱动着高通不断向前发展。也让从3G/4G时代凭借通信技术、手机SoC平台化崛起的高通,再次抓住了AI大模型这一难得的机遇。
这样的高通,自然也会成为接下来不再只关注移动设备基础处理性能,而是更关注AI性能的消费者的首选。
 币安网
币安网 欧易OKX
欧易OKX 火币全球站
火币全球站 抹茶
抹茶 芝麻开门
芝麻开门 库币
库币 Coinbase Pro
Coinbase Pro bitFlyer
bitFlyer BitMEX
BitMEX Bitstamp
Bitstamp BTC
BTC ETH
ETH USDT
USDT BNB
BNB SOL
SOL USDC
USDC XRP
XRP DOGE
DOGE TON
TON ADA
ADA