Meta普林斯顿提出LLM上下文终极解决方案!让模型化身自主智能体,自行读取上下文节点树
原文来源:新智元

图片来源:由无界AI生成
到底什么才是LLM长上下文模型的终极解决方案?
最近由普林斯顿大学和Meta AI的研究者提出了一种解决方案,将LLM视为一个交互式智能体,让它决定如何通过迭代提示来读取文本。

论文地址:https://arxiv.org/abs/2310.05029
他们设计了一种名为MemWalker的系统,可以将长上下文处理成一个摘要节点树。
收到查询时,模型可以检索这个节点树来寻找相关信息,并在收集到足够信息后做出回应。在长文本问答任务中,这个方法明显优于使用长上下文窗口、递归和检索的基线方法。
LeCun也在推上转发对他们的研究表示了支持。

MemWalker主要由两个部分构成:
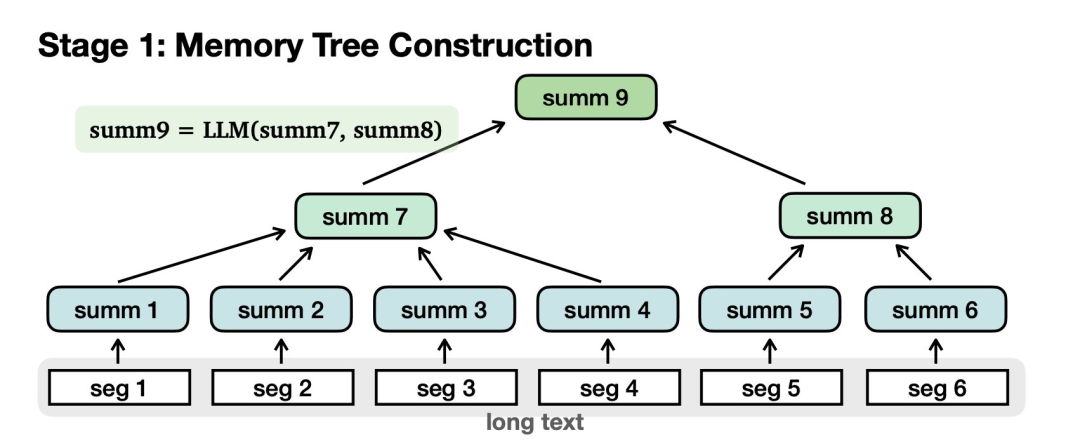
首先需要构建记忆树:
对长文本进行切分,归纳为摘要节点。汇总节点进一步汇总为更高级别的节点,最后到达根。
第二部分是导航(Navigation):
在接受查询后,LLM会在树中导航以查找相关信息并进行适当的响应。LLM通过推理来完成这一过程——可能会致力于找到某个答案,选择沿着一条路走得更远,或者发现自己误入歧途,就原路撤回。
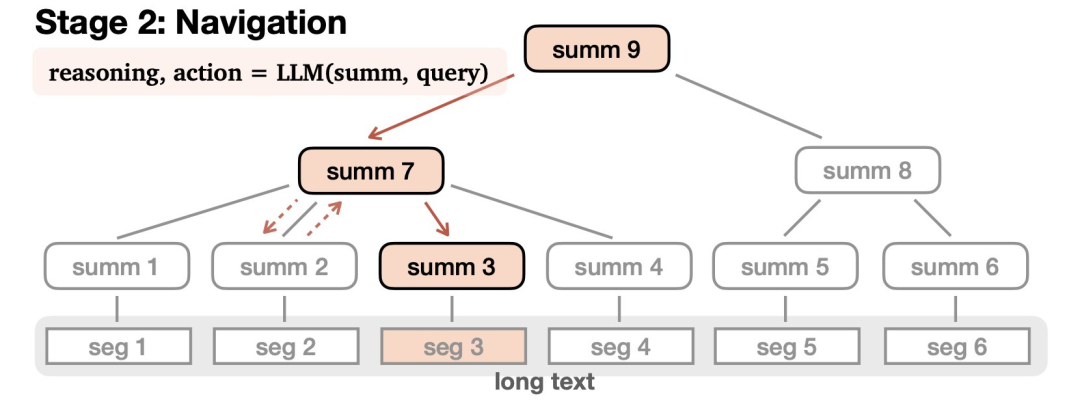
这个导航过程可以通过零样本提示来实现,并且很容易适用于指定的的任何一个大语言模型。

研究团队表明,通过对这个模型构建的记忆树的交互式读取,MemWalker 优于其他长上下文基线以及检索和循环变体,特别对于更长的例子,效果更好。
MemWalker的有效性取决于两个关键部分:
1) 工作内存大小 ——当允许 LLM 沿着其检索的路径能够获取跟多信息时,LLM 拥有更好的全局上下文能力。
2)LLM的推理能力高低——当LLM达到推理阈值时,MemWalker是有效的。当推理能力低于阈值时,导航过程中错误率就会很高。
MEMWALKER: 一个可互动读取器
研究团队研究与长上下文问答相关的任务——给定长文本x和查询q,模型的目标是生成响应r。
MEMWALKER遵循两个步骤:
1) 内存树构建,其中长上下文被拆分成树形数据结构。这种构建不依赖于查询,因此如果事先有序列数据,可以提前计算。
2) 导航,模型在接收到查询时导航此结构,收集信息以制定合适的响应。
MEMWALKER假定可以访问基础LLM,并且通过迭代LLM提示实现构建和导航。
导航
在接收到查询q后,语言模型从根节点
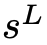
开始导航树以生成响应r。
在LLM遍历的节点
处,它观察到下一级节点
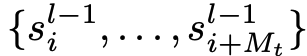
的摘要。
LLM决定在
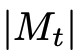
+ 1个动作中选择一个 - 选择一个子节点以进一步检查,或者返回到父节点。
在叶节点
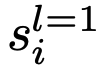
处,LLM可以决定两个动作中的一个:提交叶节点并响应查询,或者如果叶节点中的信息
(即
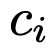
)不足,则返回到父节点
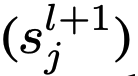
。
为了做出导航决定,研究团队也可以通过提示要求LLM首先以自然语言生成一个理由来证明动作,然后是动作选择本身。
具体地说,在每个节点,模型生成响应r ∼ LLM(r | s, q),其中响应是两个元组中的一个:1) 当LLM位于叶节点时,r = (reasoning, action, answer) 或 2) 当LLM位于非叶节点时,r = (reasoning, action)。
导航提示设计
研究团队通过零样本提示启用LLM导航。具体需要两种类型的提示:
1) 分诊提示和2) 叶提示(在下表中高亮显示)。

分诊提示包含查询、子节点的摘要和LLM应遵循的指令。分诊提示用于非叶节点。
叶提示包含段落内容、查询(和选项)以及要求LLM生成答案或返回到父节点的指令。
分诊提示和叶提示都指定了LLM需要遵循的输出格式。不遵守格式会导致无效动作,LLM需要重新生成。如果LLM连续三次未能生成可解析的输出,导航终止并返回「无答案」。
工作内存
当LLM检索完树时,它可以在导航轨迹中保持信息,并将其添加到上下文中。
准确地说,LLM生成响应r ∼ LLM(r | s, q, m),其中额外的工作内存
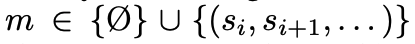
要么为空,要么包含来自先前访问过的节点的内容。
研究团队截断工作内存,使其可以适应LLM的上下文窗口。
上表也展现了如何通过[WORKING MEMORY]在提示中添加工作记忆的方式。
实验性配置
数据集和评估
研究团队使用了三个数据集:QuALITY、SummScreenFD和GovReport,这些来自SCROLLS基准测试。研究团队展示了所有数据集的准确性。
QuALITY
QuALITY是多项选择题问答数据集。
该数据集包含了来自Project Gutenberg的长篇故事和由人类注释员注释的问题。研究团队使用了187个示例的子集进行实验。
SummScreenFD
SummScreenFD是一个包含电视和电影剧本的数据集,原本是为了总结而设计的。
这些剧本以演员之间的对话形式呈现。研究团队将该数据集转换为问答任务,其中原始提供的基本真实摘要文本被用来使用Stable Beluga 2生成一个「谁」的问题,然后由人类专家检查答案。
与原始长文本配对的问题成为重新定位的QA任务的306个示例。
GovReport
GovReport数据集汇集了来自国会研究服务和美国政府问责办公室的文档,以及由专家提供的摘要。
研究团队以与SummScreenFD相同的方式将该数据集转换为包含101个示例的问答数据集。
所有三个数据集都以不同长度的长上下文作为示例特征 ,有些是较短的示例,有些是较长的序列。
因此,研究团队既展示了原始数据集上的结果,也展示了每个任务中仅包含较长序列的子集上的结果,以便更好地评估在更困难、更长的上下文情况下的内存访问。
门槛值分别是QuALITY的8000个token,SummScreenFD的6000个token和GovReport的12000个token。
模型
研究团队在大多数实验中使用Stable Beluga 2作为基础LLM,因为与其他几种LLM变体相比,它提供了最先进的性能,研究团队将展示这一点。
Stable Beluga 2是一个基于70B LLaMA-2的指令调整模型,其中微调与研究团队的评估任务不重叠。
它的最大上下文长度为4,096个token。研究团队在没有进一步微调或在上下文中为研究团队的任务提供少量示例的情况下,以零射提示的方式使用该模型。
研究团队使用顶部p采样来进行内存树构建以及生成导航的动作和推理。
研究团队分别为QuALITY、SummScreenFD和GovReport设置节点的最大数量maxt Mt = 8, 5, 8和段大小|c| = 1000, 1000, 1200。
基准
研究团队将三种基于相同底层LLM的内存技术与Stable Beluga 2进行比较:
1) 全上下文窗口
2) 递归
3) 检索
全上下文窗口基线使用全部4,096个token来处理长输入文本和生成。由于数据集中的实例经常超过上下文限制,研究团队对长度进行截断,将文本的右侧(最近)或左侧(最不近)作为输入,并评估这两种方法。
对于检索,研究团队使用Contriever(Izacard等人,2022)根据查询从长上下文中选择段落。得分最高的段落被连接为LLM的输入上下文,直到它们填满上下文。
最后,研究团队实现了一个基线,该基线通过摘要将先前段落token中的信息循环传递到当前段落,其中每个段落为2,500个token,最大摘要大小为500个token。
结果与分析
主要结果
下表2展示了MEMWALKER与其他基线之间的比较。
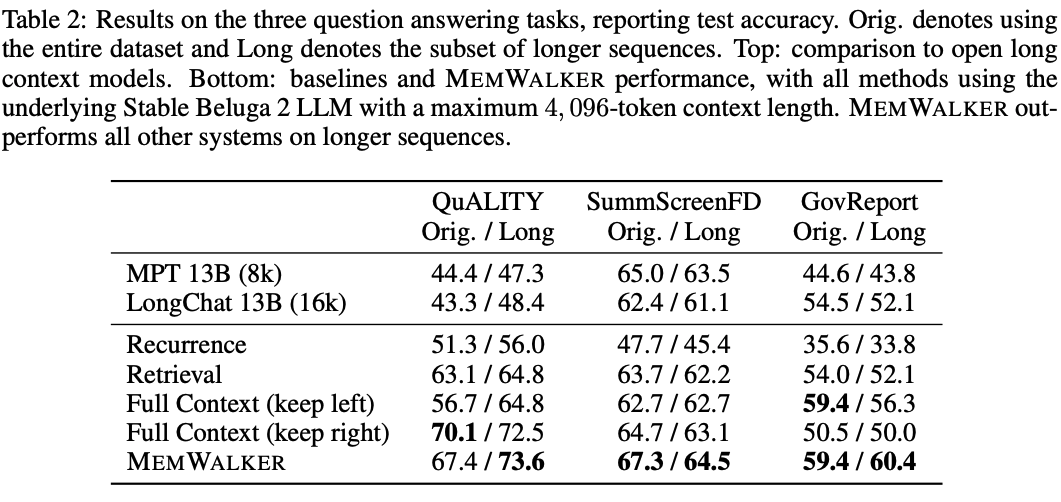
MEMWALKER在所有任务中都大幅度超越了递归基线。
这显示了递归的限制,即查询的相关信息在几步之后会丢失。
MEMWALKER也超越了检索,其中段落来自连贯的长篇故事,而不是单独的文档。
在这些任务中,全上下文基线可以在「原始」任务设置中表现良好,该设置可能包含相对较短的序列,尽管选择左或右截断以获得最佳性能似乎取决于数据集。
然而,除了QuALITY上的保持右侧变量和GovReport上的保持左侧变量外,MEMWALKER在原始设置中实现了比全上下文基线更高的性能,这可能是由于数据集中的位置偏差,其中相关段落通常出现在文本的开头或末尾。
然而,在所有三个任务的长版本上,MEMWALKER均超越所有基线,即在内存访问变得更为关键时,它表现出强劲的性能。
MEMWALKER还超越了其他公开可用的模型,包括LongChat和MPT。
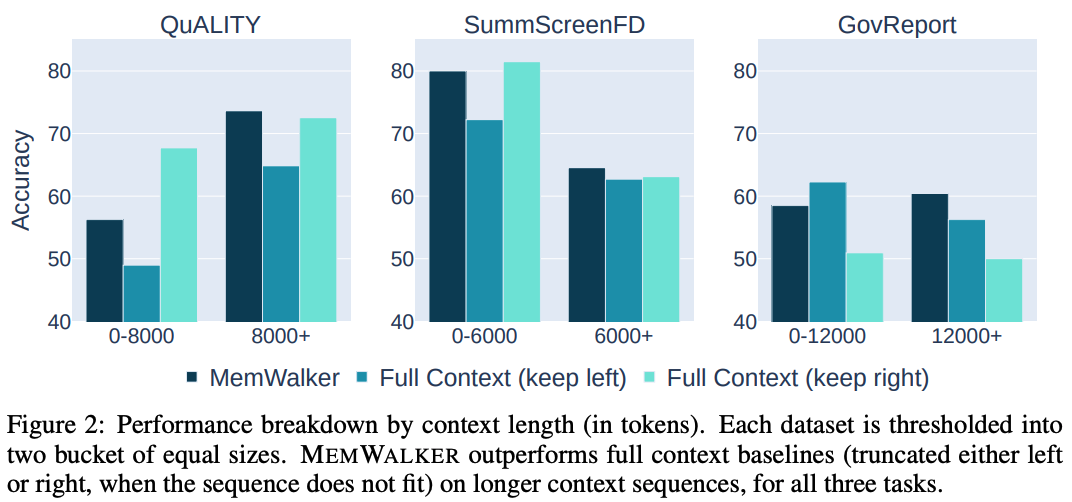
MEMWALKER提高了长序列上的性能。研究团队在上图2中为每个任务提供了输入序列长度的性能细分。
当文本长度较短时,MEMWALKER不如全上下文(左或右截断)基线,但在所有任务的较长序列上都优于两种截断类型。
交互式读取的好处在于文本长度适当增加后显现出来,即一旦序列长度明显大于LLM上下文长度的4,096,就会显示出更好的性能。
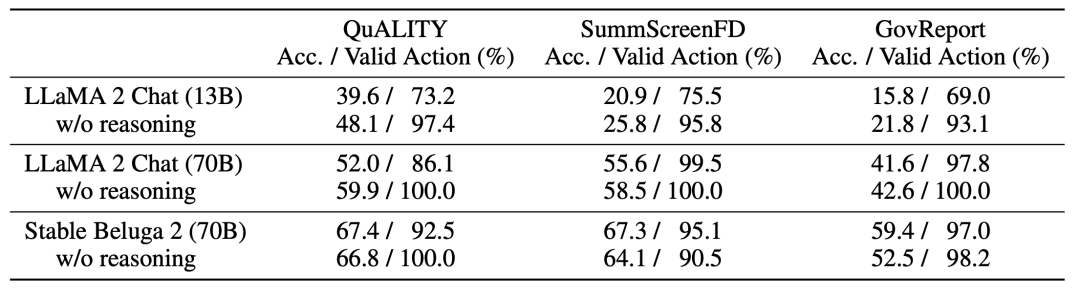
推理能力对于内存树导航至关重要。
MEMWALKER的有效性高度依赖于底层LLM的推理能力。对于每个导航决策,研究团队使用一个LLM提示,要求LLM首先以自然语言生成一个理由来证明接下来的预测动作,参见下表1。

研究团队在下表3中展示了通过比较Llama 2 Chat(13B和70B参数变体)和Stable Beluga 2(70B),并通过从提示中删除「在做出决定之前首先提供推理......」这行来展示推理如何影响性能。
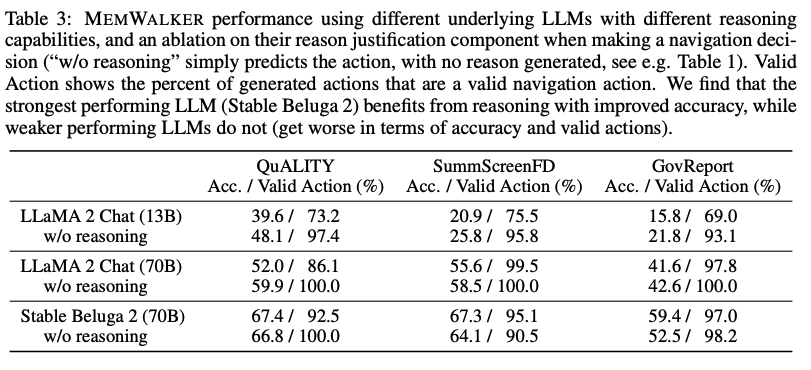
对于较小、能力较差的模型(13B),由于无法遵循指令,性能大幅落后于70B模型。实际上,为较弱的模型要求推理理由会降低性能,可能是因为它们无法生成和利用这些理由。
Stable Beluga 2的表现优于同一LLM大小的Llama 2 Chat,并且还显示出增强的推理能力。
对于Stable Beluga 2,在所有任务中要求推理理由都会提高性能。这突显了MEMWALKER的主要特点:如果LLM通过了关键推理能力阈值,它可以在多轮中对长输入进行推理,而不会在各轮之间迅速产生错误。
对于不能做出良好导航决策的较弱LLM,错误可能会累积,总体性能会受损。
随着LLM在未来几年的推理能力的不断提高,研究团队期望像MEMWALKER这样的方法会变得越来越有效。
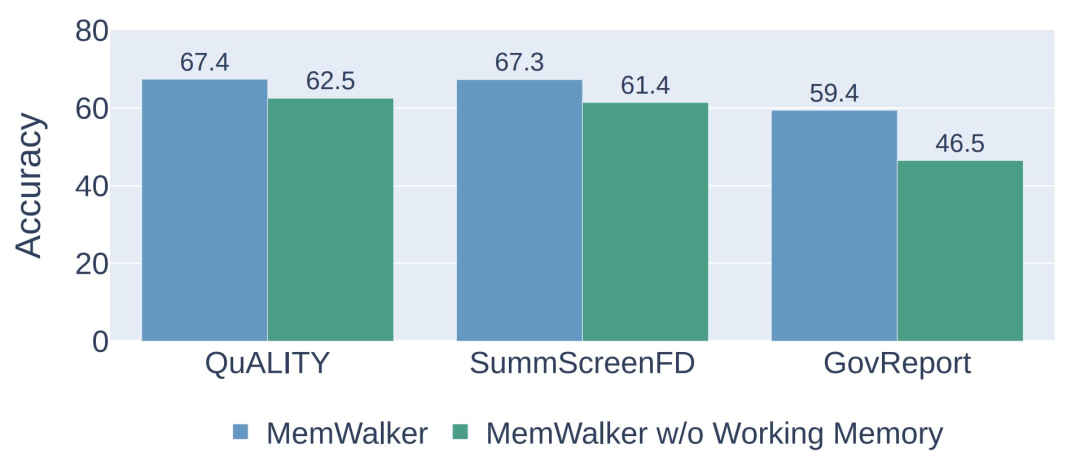
导航内存树需要工作内存。当MEMWALKER做出决策以遍历内存树并读取相关段落时,它可能会失去对整体上下文的了解。
因此,模型将沿导航路径从节点中携带信息作为工作内存,其中工作内存的内容在模型选择下一路径时更新。
研究团队评估了有无工作内存的MEMWALKER的性能,结果显示在下图3中。
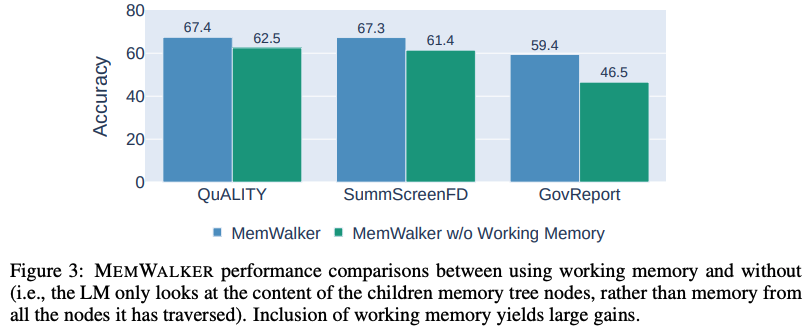
研究团队发现在所有任务中,工作内存耗尽会导致性能显著下降,准确率下降5-13%,显示了这一组件的重要性。
MEMWALKER可以从错误的路径中恢复。
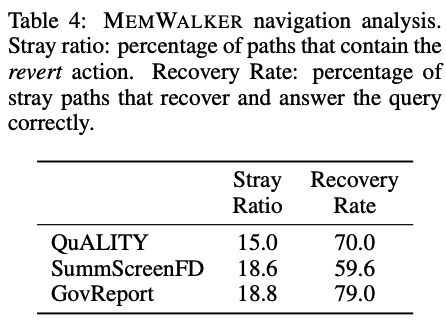
当MEMWALKER导航内存树时,它不仅需要找到通往最相关段落的路径,而且可能需要从全部检索错误中恢复。
研究团队在下表4中展示了恢复统计数据。MEMWALKER对大约15% - 20%的示例执行恢复导航操作(因此更改路径),但是在这些示例中可以恢复并在QuALITY中70%的时间内正确获得这些示例,60%适用于SummScreenFD,和∼ 80%适用于GovReport。
MEMWALKER实现了高效读取。由于MEMWALKER确定了需要读取长文本的哪些部分,因此需要读取的有效内容可能小于整个序列。
研究团队展示了所有示例的长上下文读取百分比的平均值,对于三个任务中的每一个,见下图4。研究团队发现,平均只需要读取63%-69%的文本就可以回答问题,包括树节点的内容。
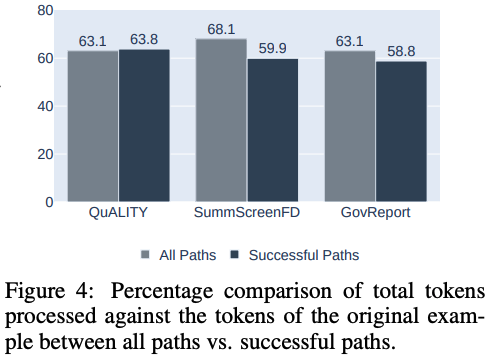
在成功的路径中,所需的阅读进一步减少到59% - 64%。
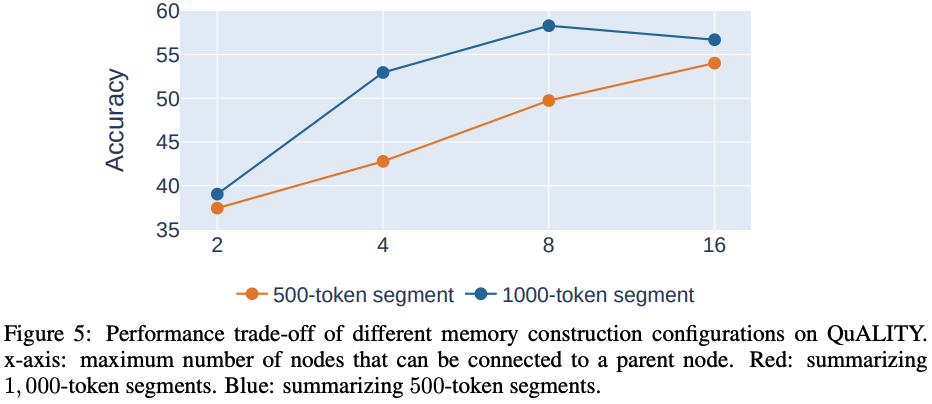
内存树构建的权衡
当研究团队构建内存树时,会出现一个基本的权衡——将更大的段落总结为节点以减少树的深度,但可能会失去内容的准确性。
类似地,将许多较低级别的节点连接到上面的节点可以帮助展平树,但可能会使每个节点上的LLM导航任务变得更为困难。
下图5显示了QuALITY上内存树的不同配置的性能。总结较大段落通常比总结较小段落以及将更多子节点连接到父节点更为有益。
然而,随着节点最大数量的增加,性能趋于平稳,显示了在内存树构建过程中可以将多少信息打包到节点中的权衡。
参考资料:
https://arxiv.org/abs/2310.05029
- 110 张图揭示加密市场现状:BTC 市占率超 52%,一季度稳定币供应量上涨 14%
- 2本周值得重点参与的3个链游项目:MapleStory Universe、AI ARENA、My Neighbor Alice「GameFi 猎手」
- 3AI 代币另一面:多数项目忙于金融利益,而非现实影响
- 4牛市如何暴富?关于加密市场的6点思考
- 5香港现货ETF即将上市,还有哪些「香港概念」项目值得关注?
- 6加密货币文化的无限潜力
- 7Bitget研究院:Runes协议上线导致BTC网络费用激增,BONK领涨Solana Meme
- 8Gate.io创始人韩林TOKEN2049周边活动演讲:基础设施是区块链大规模采用的关键
- 9Movement Labs完成3800万美元A轮融资,旨在将MoveVM引入以太坊
 币安网
币安网 欧易OKX
欧易OKX 火币全球站
火币全球站 抹茶
抹茶 芝麻开门
芝麻开门 库币
库币 Coinbase Pro
Coinbase Pro bitFlyer
bitFlyer BitMEX
BitMEX Bitstamp
Bitstamp BTC
BTC ETH
ETH USDT
USDT BNB
BNB SOL
SOL USDC
USDC XRP
XRP DOGE
DOGE TON
TON ADA
ADA