3万亿训练数据,可商用,媲美Llama2!阿里云开源通义千问14B
原文来源:AIGC开放社区

图片来源:由无界 AI 生成
阿里云官宣开源Qwen-14B和Qwen-14B-Chat模型,通过文本问答方式可自动生成文本/代码、总结文本摘要、翻译、分析代码等。
据悉,Qwen-14B是在3万亿token高质量数据上进行稳定的预训练,允许商业化,最大支持8k的上下文窗口长度,在多个权威评测中超越同等规模模型,部分指标媲美Llama2-70B。
前不久,阿里云曾开源了Qwen-7B系列模型,仅一个多月的时间下载量就突破100万,成为最强中文开源大模型之一。而此次的Qwen-14B在训练数据、参数等全面增强,帮助企业、个人开发者打造专属生成式AI助手。

魔搭地址:https://www.modelscope.cn/models/qwen/Qwen-14B-Chat/summary
https://www.modelscope.cn/models/qwen/Qwen-14B/summary
HuggingFace地址:https://huggingface.co/Qwen/Qwen-14B
https://huggingface.co/Qwen/Qwen-14B-Chat
Github地址:https://github.com/QwenLM/Qwen
免费在线体验:https://modelscope.cn/studios/qwen/Qwen-14B-Chat-Demo/summary
论文:https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf
通义千问-14B技术亮点
高质量训练数据:通义千问-14使用超过3万亿tokens的数据进行预训练,包含高质量中、英、多语言、代码、数学等,涵盖通用及专业领域的训练语料。同时通过大量对比实验的方式,对预训练语料分布进行了优化。
性能强大:Qwen-14B在多个中英文下游评测任务上,涵盖常识推理、代码、数学、翻译等,效果显著超越同等规模的开源模型,甚至在部分指标上相比更大尺寸模型也有较强竞争力。
词表覆盖更全面:相比目前以中英词表为主的开源模型,Qwen-14B使用了约15万大小的词表。该词表对多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强和扩展。
性能评测
Qwen-14B选取了MMLU、C-Eval、GSM8K、MATH、HumanEval、MBPP、BBH、CMMLU等目前较流行的评测平台,对模型的中英知识能力、翻译、数学推理、代码等能力进行综合评测。
Qwen-14B在所有评测平台的测试中,均取得了同级别开源模型中的最优表现。
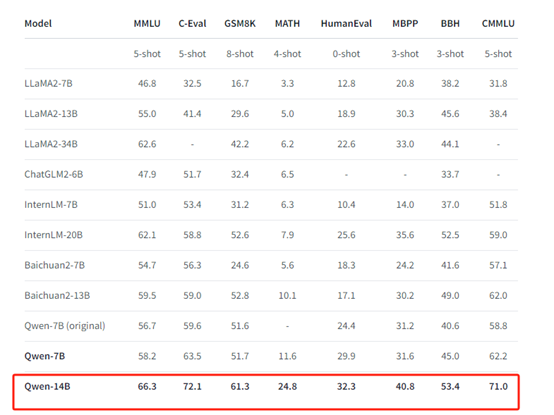
此外,阿里云提供了评测脚本(https://github.com/QwenLM/Qwen/tree/main/eval),方便大家复现模型效果。注意:由于硬件和框架造成的舍入误差,复现结果如有小幅波动属于正常现象。
Qwen-14B模型技术细节
在位置编码、FFN激活函数和normalization的实现方式上,阿里云采用了目前最流行的做法, 即RoPE相对位置编码、SwiGLU激活函数、RMSNorm(可选安装flash-attention加速)。
在分词器方面,相比目前主流开源模型以中英词表为主,Qwen-14B使用了超过15万token大小的词表。
该词表在GPT-4使用的BPE词表cl100k_base基础上,对中文、多语言进行了优化,在对中、英、代码数据的高效编解码的基础上,对部分多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强。词表对数字按单个数字位切分。调用较为高效的tiktoken分词库进行分词。
阿里云从部分语种各随机抽取100万个文档语料,以对比不同模型的编码压缩率(以支持100语种的XLM-R为基准值1,越低越好)。
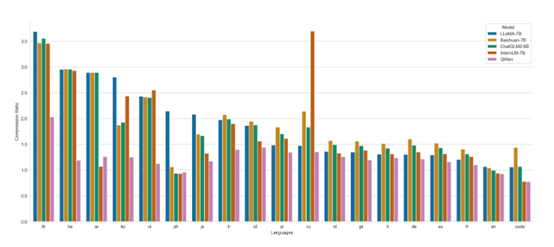
可以看到Qwen-14B在保持中英代码高效解码的前提下,对部分使用人群较多的语种(泰语th、希伯来语he、阿拉伯语ar、韩语ko、越南语vi、日语ja、土耳其语tr、印尼语id、波兰语pl、俄语ru、荷兰语nl、葡萄牙语pt、意大利语it、德语de、西班牙语es、法语fr等)上也实现了较高的压缩率,使得模型在这些语种上也具备较强的可扩展性和较高的训练和推理效率。
在预训练数据方面,Qwen-14B模型一方面利用了部分开源通用语料, 另一方面也积累了海量全网语料以及高质量文本内容,去重及过滤后的语料超过3T tokens。囊括全网文本、百科、书籍、代码、数学及各个领域垂类。
- 110 张图揭示加密市场现状:BTC 市占率超 52%,一季度稳定币供应量上涨 14%
- 2本周值得重点参与的3个链游项目:MapleStory Universe、AI ARENA、My Neighbor Alice「GameFi 猎手」
- 3AI 代币另一面:多数项目忙于金融利益,而非现实影响
- 4香港现货ETF即将上市,还有哪些「香港概念」项目值得关注?
- 5牛市如何暴富?关于加密市场的6点思考
- 6加密货币文化的无限潜力
- 7Movement Labs完成3800万美元A轮融资,旨在将MoveVM引入以太坊
- 8灰度报告:以太坊区块链在代币化趋势中最具潜力
- 9Gate.io创始人韩林TOKEN2049周边活动演讲:基础设施是区块链大规模采用的关键
 币安网
币安网 欧易OKX
欧易OKX 火币全球站
火币全球站 抹茶
抹茶 芝麻开门
芝麻开门 库币
库币 Coinbase Pro
Coinbase Pro bitFlyer
bitFlyer BitMEX
BitMEX Bitstamp
Bitstamp BTC
BTC ETH
ETH USDT
USDT BNB
BNB SOL
SOL USDC
USDC XRP
XRP DOGE
DOGE TON
TON ADA
ADA