阿里140亿大模型开源!10项任务超340亿Llama 2,Demo在线可玩
原文来源:量子位

图片来源:由无界 AI生成
阿里又开源大模型了!
这次是纯粹的大语言模型,相比上一次的70亿,新模型的参数量来到了140亿。
它名叫Qwen-14B,一上来就在一系列任务榜单中全部取得了第一,直接超过了Meta的340亿参数Llama 2版本。
Qwen-14B的训练数据达到3万亿tokens,不仅中英文都来得,序列长度也达到了8192。
用法也是老样子,完全开源,而且免费可用,目前在魔搭社区上已经可以试玩到Demo版本。
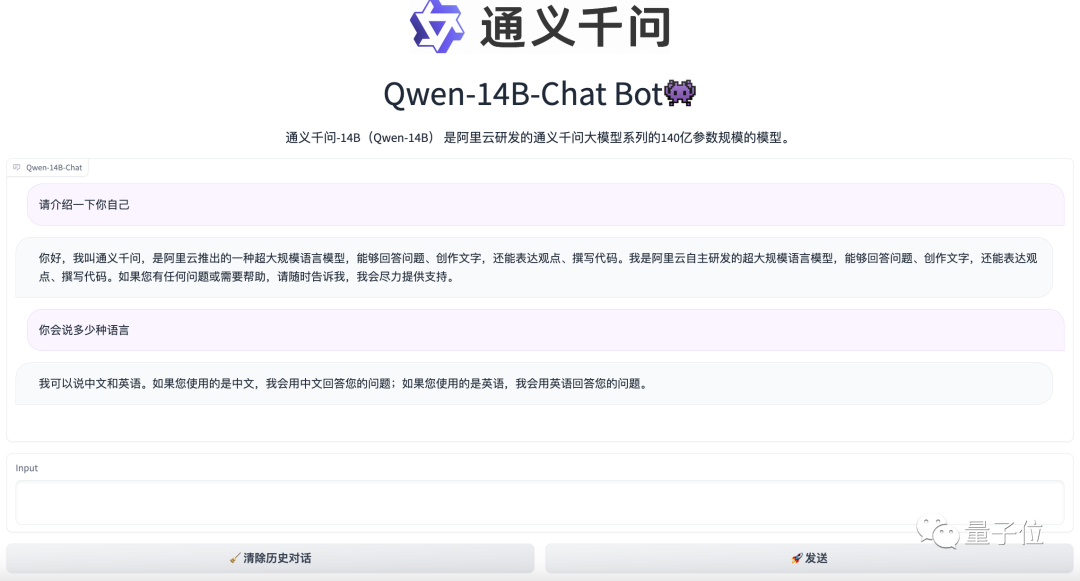
看起来,阿里的Qwen颇有点对标Meta的Llama,要搞出一整套“国内大模型开源全系列”那味了。
那么,Qwen-14B的效果究竟怎么样呢?我们这就试一试。
10个榜单超越340亿Llama 2
先来看看Qwen-14B的整体表现如何。
虽然Llama 2取得了一系列不错的“战绩”,不过至少官方提供的版本中,还不太具备说中文的能力。
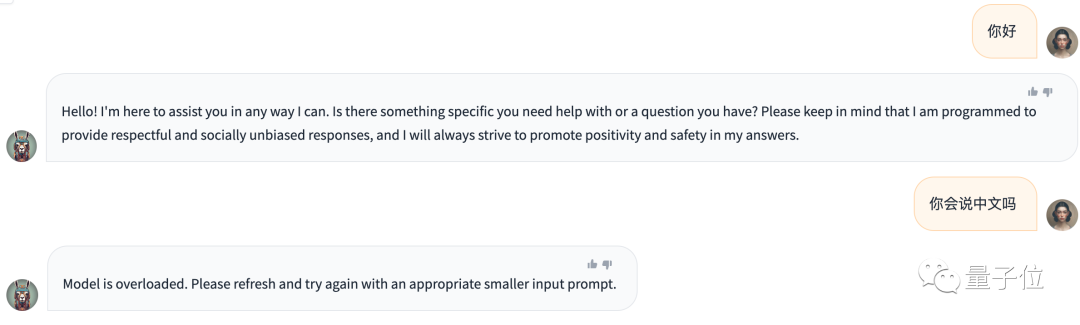
因此,我们先来看看Qwen-14B的中文能力如何,然后再试试它在其他学科上的水平。
老样子,弱智benchmark送上:

看起来Qwen-14B也能准确应对。稍微难点的中文理解题:

感觉还不错,顺便纠正了我的语病(手动狗头)。
那么,数学题表现如何呢?普通的鸡兔同笼试试:
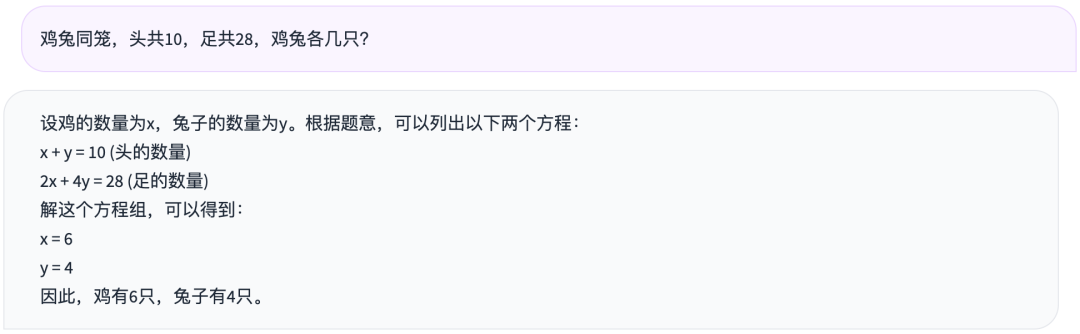
表现也中规中矩。再试试稍微难一点的逻辑推理题,之前有人测试发现,60个大模型全部做错了。
问题如下:
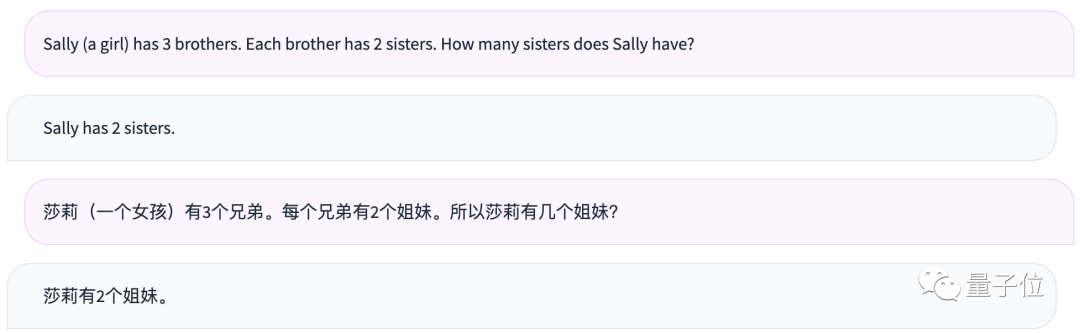
Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have?
莎莉(一个女孩)有3个兄弟。每个兄弟有2个姐妹。所以莎莉有几个姐妹?
PS:这道题的正确答案是1。
在做错的一系列大模型中,包括GPT-4和Claude 2,也包括Llama 2:

很遗憾,这里Qwen-14B也没做出来。
不过它的代码能力还可以,例如让写一下贪吃蛇的代码:
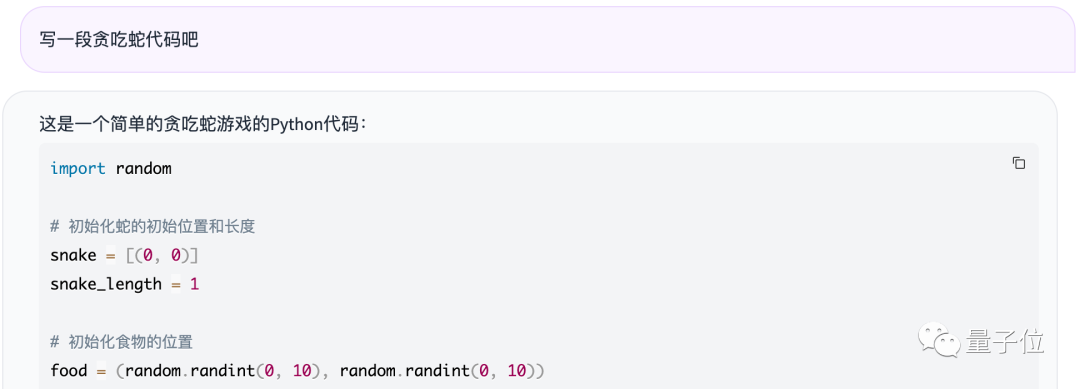
它很快给出了一个完整版的贪吃蛇代码出来,带注释那种:
import random
# 初始化蛇的初始位置和长度
snake = [(0, 0)]
snake_length = 1
# 初始化食物的位置
food = (random.randint(0, 10), random.randint(0, 10))
# 初始化游戏的分数
score = 0
# 初始化游戏的结束标志
game_over = False
# 游戏主循环
while not game_over:
# 打印游戏界面
for i in range(11):for j in range(11):if (i, j) in snake:print("O", end="")elif (i, j) == food:print("F", end="")else:print(".", end="")print()
# 获取用户的输入
direction = input("Enter direction (up, down, left, right): ")
# 更新蛇的位置
if direction == "up":
snake.insert(0, (snake[0][0], snake[0][1] - 1))elif direction == "down":
snake.insert(0, (snake[0][0], snake[0][1] + 1))elif direction == "left":
snake.insert(0, (snake[0][0] - 1, snake[0][1]))elif direction == "right":
snake.insert(0, (snake[0][0] + 1, snake[0][1]))
# 更新蛇的长度
snake_length += 1
# 如果蛇吃到了食物,更新食物的位置和分数
if snake[0] == food:
food = (random.randint(0, 10), random.randint(0, 10))
score += 1
# 如果蛇撞到了墙或者自己的身体,游戏结束
if snake[0][0] < 0 or snake[0][0] >= 11 or snake[0][1] < 0 or snake[0][1] >= 11 or snake[0] in snake[1:]:
game_over = True
# 打印游戏的分数
print("Score: ", score)
# 打印游戏结束的消息
print("Game over!")试了一下,可以直接运行玩耍:
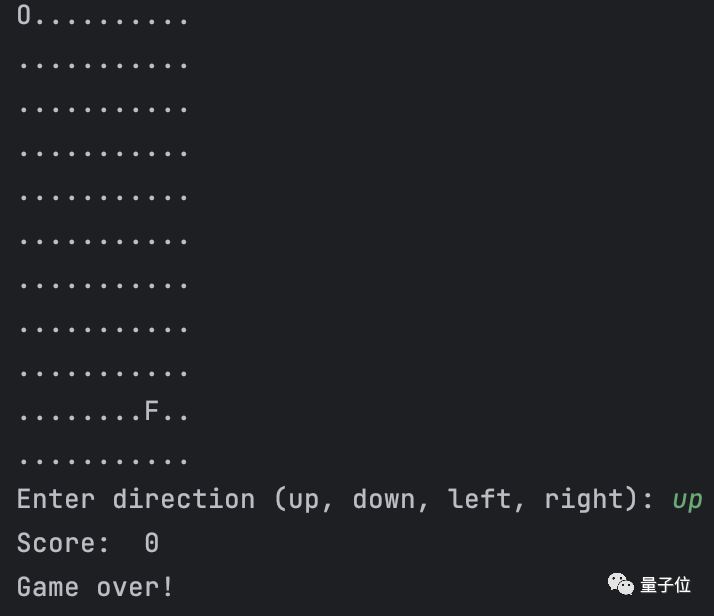
据了解,Qwen-14B和Qwen-7B一样,所具备的也不仅仅是对话功能。
除了上述能力,Qwen-14B也学会了自己调用工具。
例如,基于Code Interpreter(代码解释器)工具执行Python代码,直接做数学计算、数据分析和数据图表绘制。

团队也升级了Qwen-14B对接外部系统的技巧,不仅几步就能调用复杂插件,还能将它作为基座模型开发Agent等AI系统、完成复杂任务。
事实上,背后的Qwen-14B模型,也是个打榜小能手。
无论是在语言能力测试集上,如大规模多任务语言测评榜单MMLU、中文基础能力评估数据集C-Eval中;
还是在数学等其他学科的能力上,如小学数学加减乘除运算题GSM8K、数学竞赛数据集MATH等:
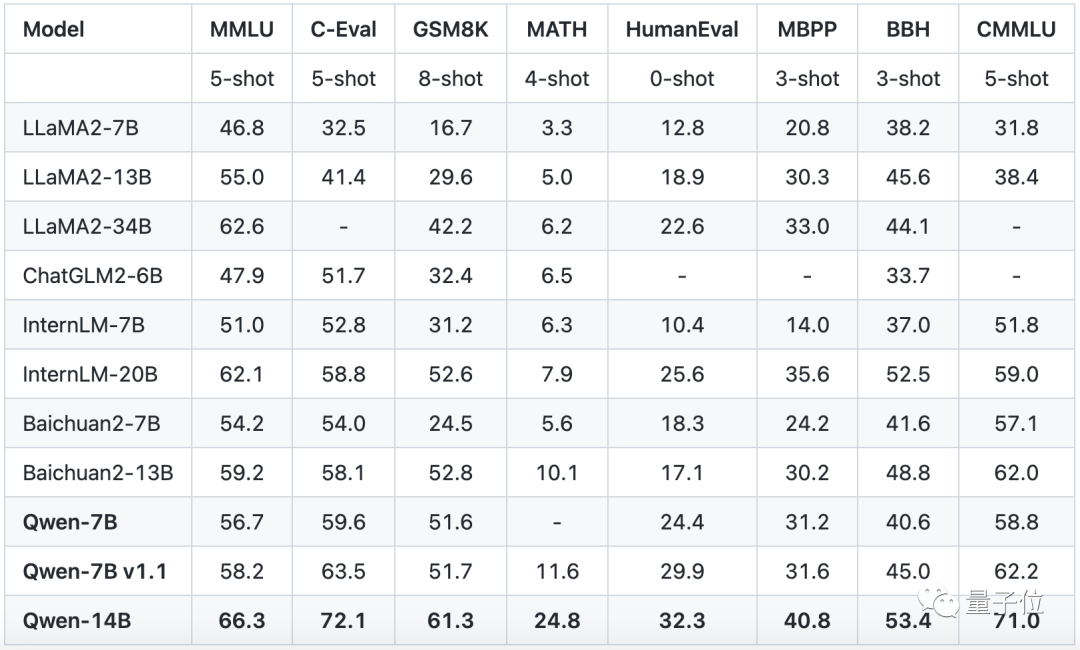
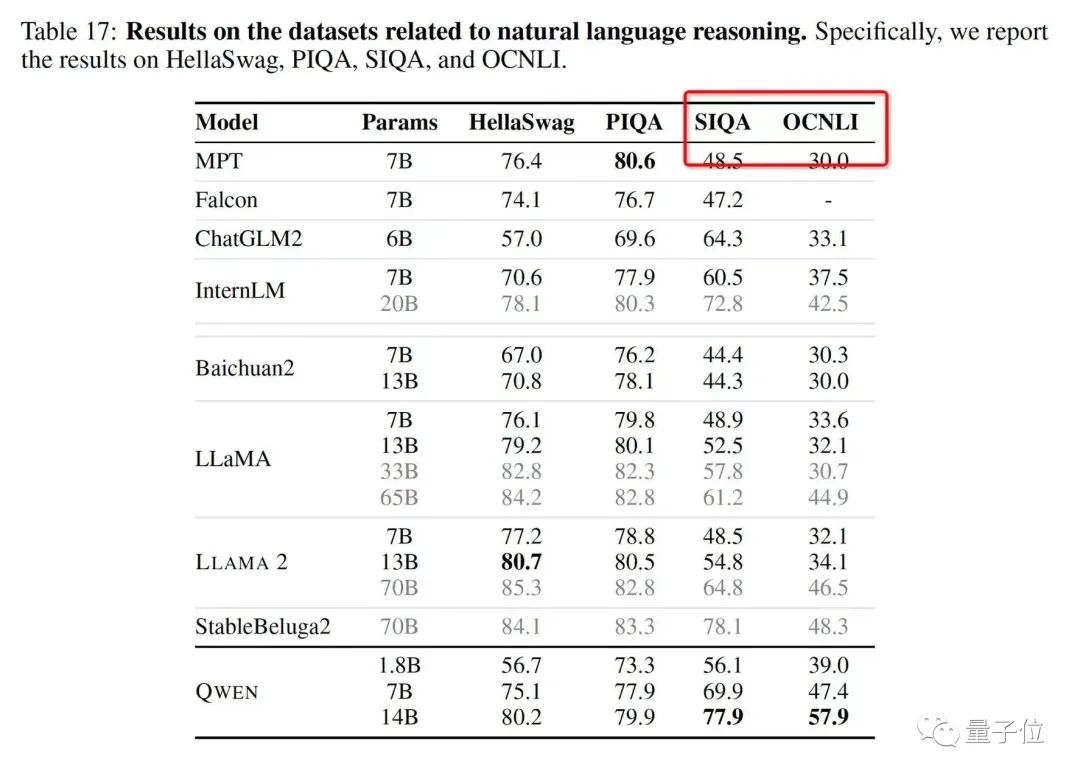
前后一共10个榜单,都取得了TOP 1的名次。
所以,Qwen-14B究竟是怎么做出来的?
训练数据超3万亿tokens
技术细节,还得从Qwen-14B的架构和训练数据说起。
作为一个参数140亿的大模型,Qwen-14B的结构细节长这样:
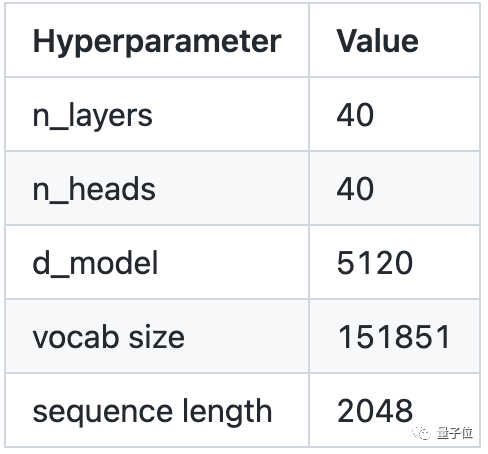
在整体架构上,团队借鉴了一些当前开源大模型的“神奇设计”,包括谷歌的PaLM以及Meta的Llama等。
包括SwiGLU的激活函数设计、ROPE的位置编码等,都有出现在Qwen-14B的结构设计中。
不仅如此,团队也针对词表和长序列数据建模进行了优化。词表大小超过15万,更节省token数。
长序列数据建模上,则采取了一些当前最有效的方法,包括但不限于Dynamnic NTK、Log-N attention scaling、window attention等,确保模型表现效果更稳定。
这也是模型虽然只有140亿,但序列长度能达到8192的原因。
之所以能取得不错的效果,也与Qwen-14B的训练数据分不开。
Qwen-14B整体采用了超过3万亿tokens数据训练。
这里面不仅仅包含语数英等基础学科,还包括了理化生政史地等多个其他学科的知识、以及代码知识,直接接受了9年义务教育(手动狗头)。
除此之外,团队还进一步做了不少数据处理工作,包括大规模数据去重、垃圾文本过滤、以及提升高质量数据比例等。
同时,为了让模型更好地学会调用工具、增强记忆能力,团队也在微调样本上进行了优化,建立更全面的自动评估基准来发现Qwen-14B表现不稳定的情況,并针对性地使用Self-Instruct方法扩充了高质量的微调样本。
事实上,这已经是通义千问系列的第三波开源了。
最早在8月初,阿里云就开源了中英文通用模型Qwen-7B和对话模型Qwen-7B-Chat。

Qwen-7B支持8K上下文长度,基于超过2.2万亿tokens包含文本、代码等类型的数据集训练,也支持插件调用和开发Agent等AI系统。
项目一开源,就冲上GitHub热榜,目前已经收获4k星热度。

(值得一提的是,这次阿里云除了发布Qwen-14B以外,也顺带升级了一波Qwen-7B)
随后在8月底,阿里云再次推出视觉语言大模型Qwen-VL。
Qwen-VL基于Qwen-7B为基座语言模型研发,支持图像、文本、检测框等多种输入,并且在文本之外,也支持检测框输出。

从demo展示中来看,Qwen-VL身兼多种能力,中英文对话、代码图像理解都来得:
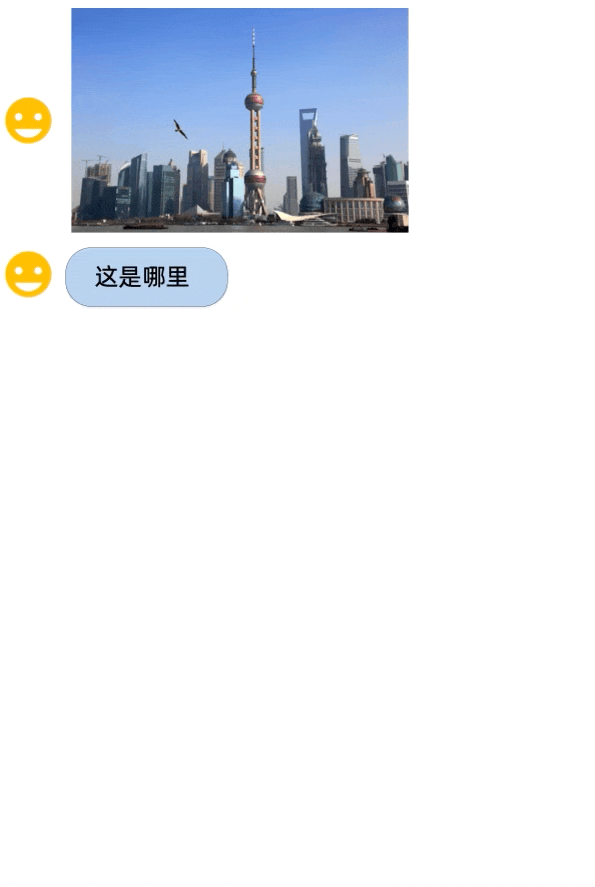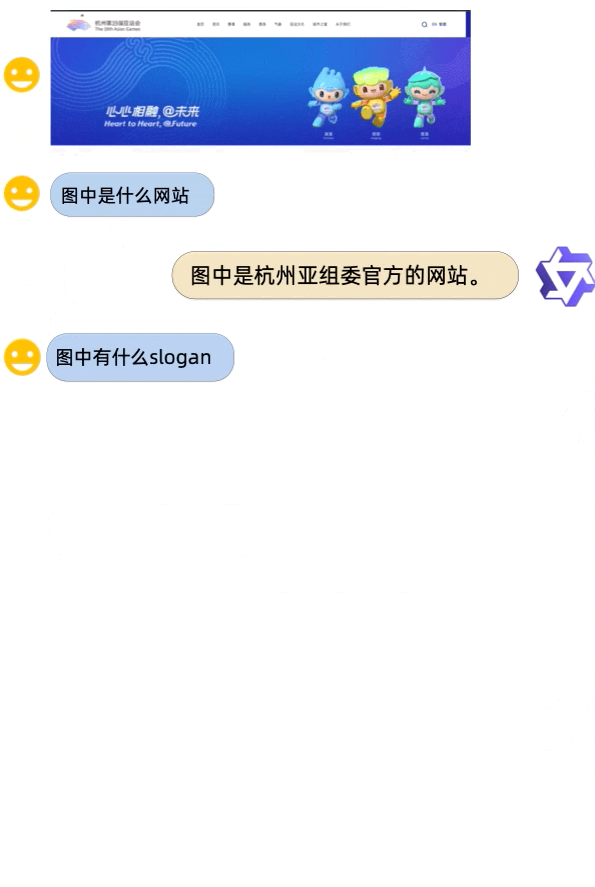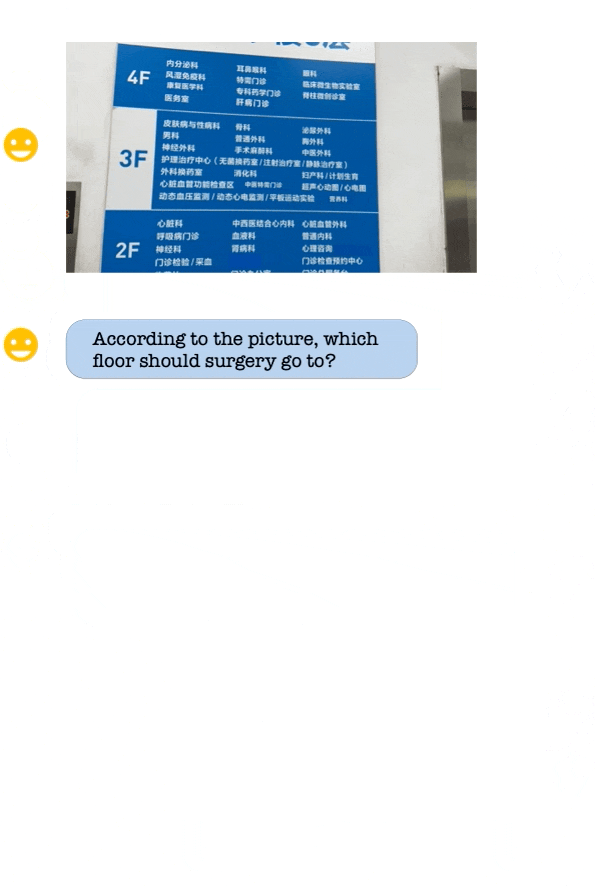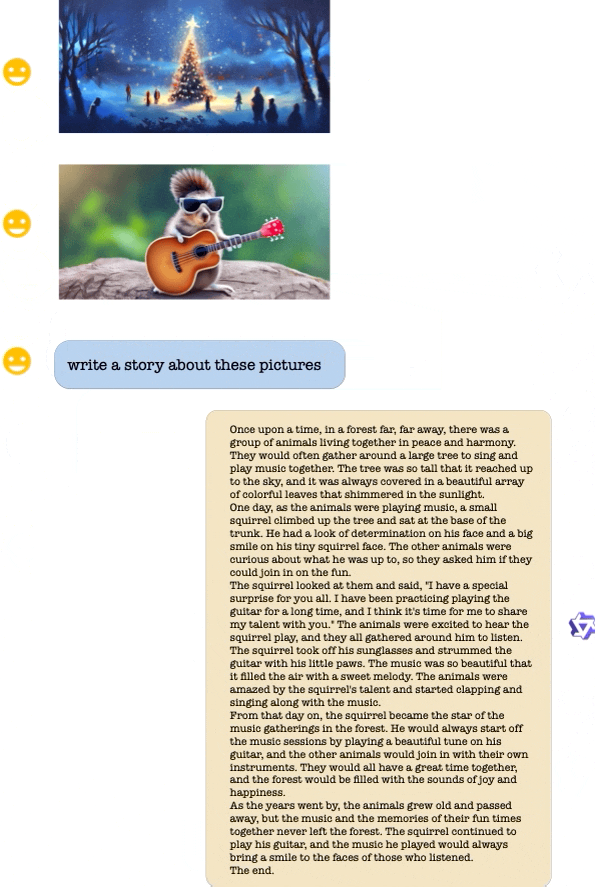
对于阿里的一系列Qwen开源大模型感兴趣的,可以去项目主页试玩一波了~
试玩地址:
https://modelscope.cn/studios/qwen/Qwen-14B-Chat-Demo/summary
参考链接:
[1]https://github.com/QwenLM/Qwen-7B
[2]https://github.com/QwenLM/Qwen-VL
[3]https://benchmarks.llmonitor.com/sally
- 1USDT市值突破1100亿美元
- 210 张图揭示加密市场现状:BTC 市占率超 52%,一季度稳定币供应量上涨 14%
- 3加密市场情绪研究报告(2024.04.15-04.19):短期下跌需要做好防御措施
- 4AI 代币另一面:多数项目忙于金融利益,而非现实影响
- 5金色早报丨加密货币价值观仍在全球范围内遭受攻击 铭文某种程度算是符文的试验田
- 6上线 Runes 自研市场:如何通过OKX Web3 钱包一站式探索符文生态
- 7Bitget研究院:Runes协议上线导致BTC网络费用激增,BONK领涨Solana Meme
- 8一周融资速递 | 33家项目获投,已披露融资总额约1.26亿美元(4.15-4.21)
- 9金色早报丨Unicross开通Merlin符文跨链桥 DePIN项目累计融资超过10亿美元
 币安网
币安网 欧易OKX
欧易OKX 火币全球站
火币全球站 抹茶
抹茶 芝麻开门
芝麻开门 库币
库币 Coinbase Pro
Coinbase Pro bitFlyer
bitFlyer BitMEX
BitMEX Bitstamp
Bitstamp BTC
BTC ETH
ETH USDT
USDT BNB
BNB SOL
SOL USDC
USDC XRP
XRP DOGE
DOGE TON
TON ADA
ADA