A卡跑大模型,性能达到4090的80%,价格只有一半:陈天奇TVM团队出品
编辑:泽南
最近,科技领域有很多人都在为算力发愁。

OpenAI CEO 奥特曼:我整天在都想着 flops。
自预训练大模型兴起以来,人们面临的算力挑战就变得越来越大。为此,人们为大语言模型(LLM)提出了许多训练和推理的解决方案。显然,大多数高性能推理解决方案都基于 CUDA 并针对英伟达 GPU 进行了优化。
但在动辄千亿参数的模型体量,多家科技公司激烈竞争,以及单一供应商的合力作用下,想抢到 GPU 又变成了一件难事。
最近,微软、OpenAI 等公司都表示正在采取必要措施来缓解用于 AI 任务的 H100、A100 专用 GPU 的短缺问题。微软正在限制员工访问 GPU 的时间,Quora 首席执行官表示,硬件短缺掩盖了人工智能应用程序的真正潜力。伊隆・马斯克还开玩笑说,企业级 GPU 比买「药」还难。
马斯克预测 GPT-5 大概需要三到五万块 H100 来训练。
旺盛的需求除了推动英伟达的股价,使其改变生产计划之外,也让人们不得不去寻求其他替代方式。好消息是,图形芯片市场上并不只有 N 卡一家。
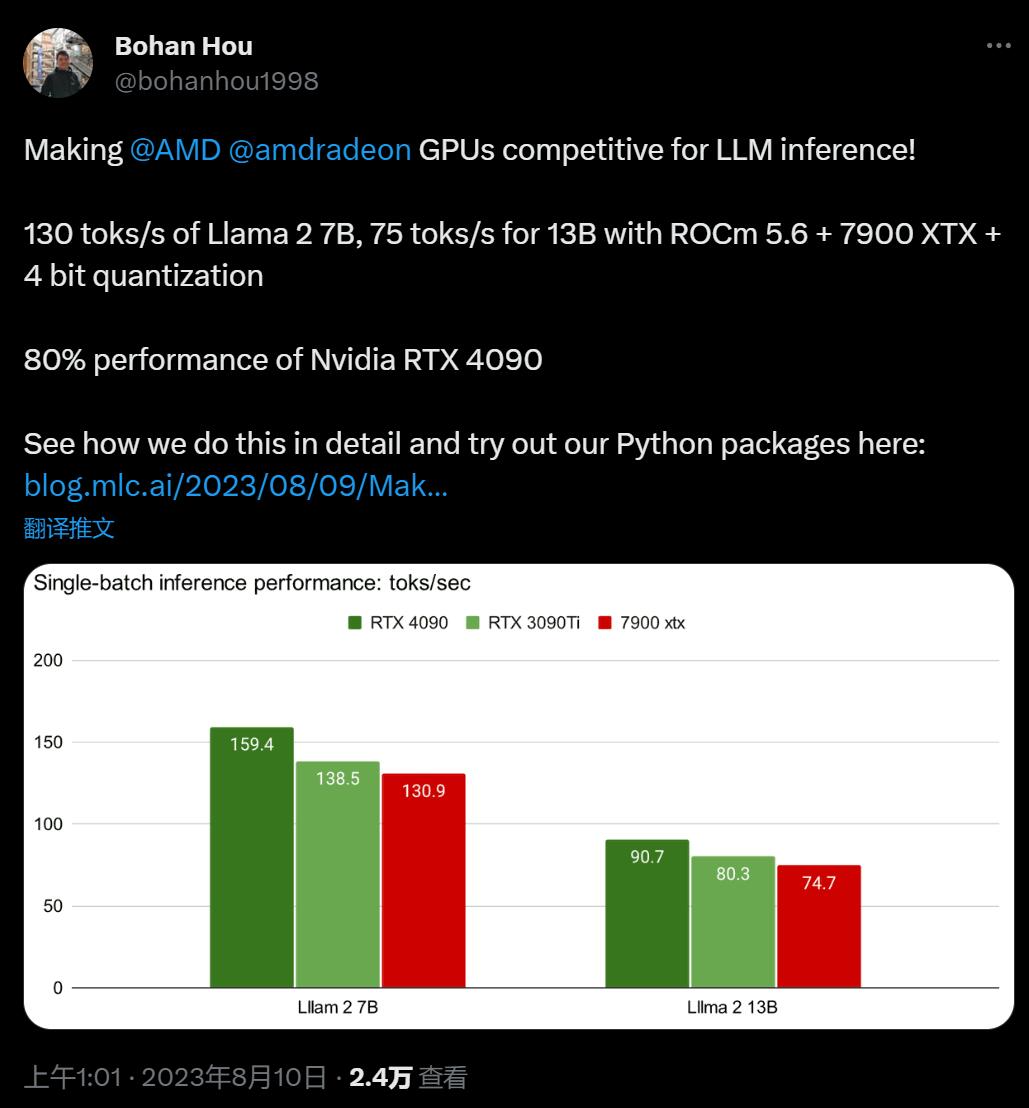
昨天,卡耐基梅隆大学博士生侯博涵(Bohan Hou)放出了使用 AMD 显卡进行大模型推理的新方案,立刻获得了机器学习社区的关注。
在 CMU,侯博涵的导师是 TVM、MXNET、XGBoost 的作者陈天奇。对于这项新实践,陈天奇表示,解决 AI 硬件短缺问题的方法还是要看软件,让我们带来高性能、通用部署的开源大模型吧。

在知乎上,作者对于实现高性能 LLM 推理进行了详细介绍:
通过这种优化方法,在最新的 Llama2 的 7B 和 13B 模型中,如果用一块 AMD Radeon RX 7900 XTX 速度可以达到英伟达 RTX 4090 的 80%,或是 3090Ti 的 94%。
除了 ROCm 之外,这种 Vulkan 支持还允许我们把大模型的部署推广到其他 AMD 芯片类型上,例如具有 AMD APU 的 SteamDeck。
如果粗略的比较一下规格,我们可以看到 AMD 的 RX 7900 XTX 与英伟达的 RTX 4090 和 RTX 3090 Ti 处于相近级别。
它们的显存都在 24GB,这意味着它们可以容纳相同尺寸的模型,它们都具有相似的内存带宽。
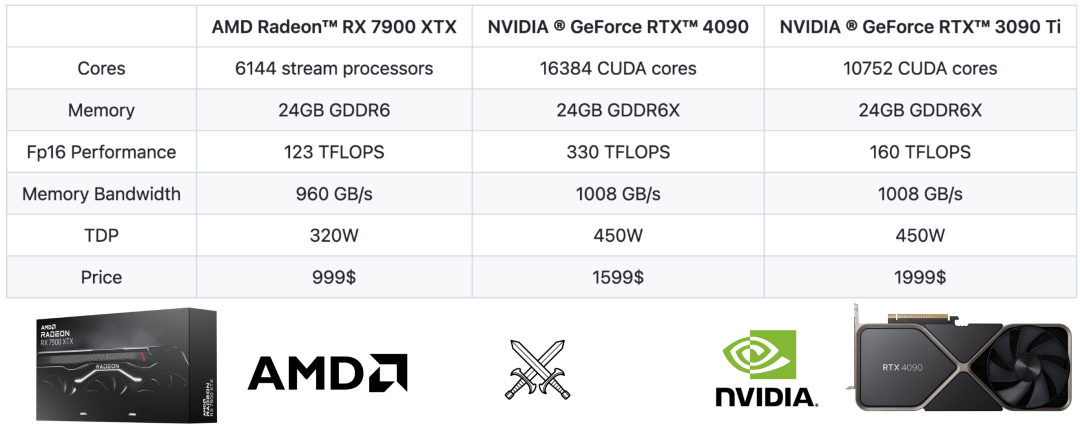
但是在算力上,RTX 4090 的 FP16 性能比 7900 XTX 高两倍,而 3090 Ti 的 FP16 性能比 7900 XTX 高 1.3 倍。如果只考虑延迟敏感的大模型推理,其性能主要受内存限制,因此 FP16 性能不是这里的瓶颈。
而看价格的话,RX 7900 XTX 比 RTX 4090 便宜 40% 还多(京东上看甚至有 50%),在消费级领域里前者几乎是和 RTX 4080 对标的。
3090Ti 的价格则很难比较,毕竟那是上一代产品。但从纯硬件规格的角度来看,AMD 7900 XTX 似乎与 RTX 3090 Ti 相当。
我们知道,硬件层的算力并不一定是 AMD 长期以来在机器学习上落后的原因 —— 主要差距在于缺乏相关模型的软件支持和优化。从生态角度来看,有两个因素已开始改变现状:
AMD 正在努力在 ROCm 平台上增加投入。
机器学习编译等新兴技术现在有助于降低跨后端的,更通用软件支持的总体成本。
研究人员深入讨论了 AMD GPU 体系与目前流行的英伟达 GPU 上高性能 CUDA 解决方案相比的表现如何。
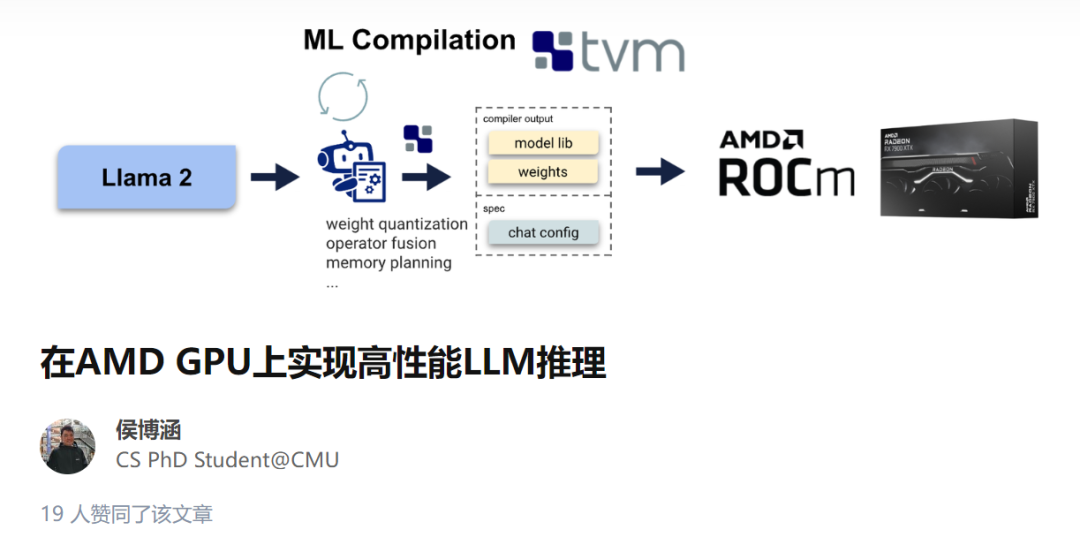
用 ROCm 进行机器学习编译
机器学习编译
机器学习编译是一种用于编译和自动优化机器学习模型的新兴技术。MLC 解决方案不是为每个后端(如 ROCm 或 CUDA)编写特定的算子 ,而是自动生成适用于不同后端的代码。在这里,作者利用 MLC-LLM,一种基于机器学习编译的解决方案,提供了 LLM 的高性能通用部署。MLC-LLM 建立在 Apache TVM Unity 之上,后者是一个机器学习编译软件栈,提供了基于 Python 的高效开发和通用部署。MLC-LLM 为各种后端(包括 CUDA、Metal、ROCm、Vulkan 和 OpenCL)提供了最先进的性能,涵盖了从服务器级别 GPU 到移动设备(iPhone 和 Android)。
整体而言,MLC-LLM 允许用户使用基于 Python 的工作流程获取开源的大语言模型,并在包括转换计算图、优化 GPU 算子的张量 layout 和 schedule 以及在感兴趣的平台上本地部署时进行编译。
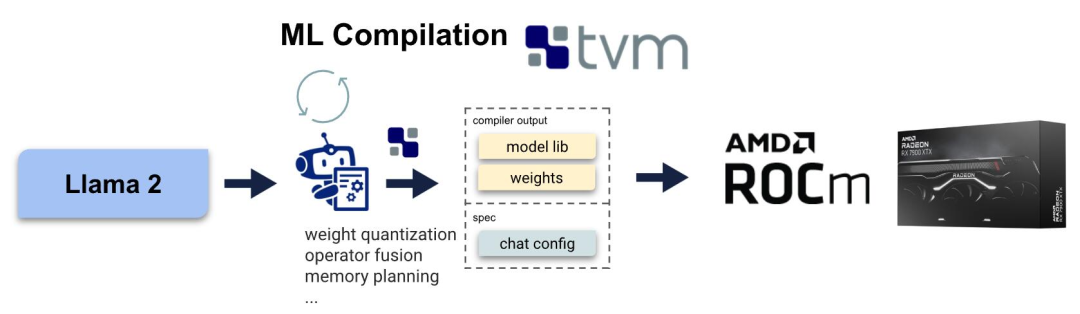
面向 ROCm 的机器学习编译技术栈。
针对 AMD GPU 和 APU 的 MLC
人们对于 A 卡用于机器学习的探索其实并不鲜见,支持 AMD GPU 有几种可能的技术路线:ROCm、OpenCL、Vulkan 和 WebGPU。ROCm 技术栈是 AMD 最近推出的,与 CUDA 技术栈有许多相应的相似之处。Vulkan 是最新的图形渲染标准,为各种 GPU 设备提供了广泛的支持。WebGPU 是最新的 Web 标准,允许在 Web 浏览器上运行计算。
虽然有这么多可能的路线,但很少有解决方案支持除了 CUDA 之外的方法,这在很大程度上是因为复制新硬件或 GPU 编程模型的技术栈的工程成本过高。MLC-LLM 支持自动代码生成,无需为每个 GPU 算子重新定制,从而为以上所有方法提供支持。但是,最终性能仍然取决于 GPU 运行时的质量以及在每个平台上的可用性。
在这个案例中,作者选择 Radeon 7900 XTX 的 ROCm 和 Steamdeck 的 APU 的 Vulkan,可以发现 ROCm 技术栈是开箱即用的。由于 TVM unity 中具有高效的基于 Python 的开发流程,花费了若干小时来进一步提供 ROCm 的性能优化。具体来说,研究人员采取了以下措施来提供 ROCm 支持:
重用现有后端(如 CUDA 和 Metal)的整个 MLC 流水线,包括内存规划、算子融合等。
重用 TVM TensorIR 中的通用 GPU 算子优化空间,并将其后端选为 AMD GPU
重用 TVM 的 ROCm 代码生成流程,通过 LLVM 生成 ROCm 代码。
最后,将生成的代码导出为可以由 CLI、Python 和 REST API 调用的共享或静态库。
使用 MLC Python 包进行性能测试
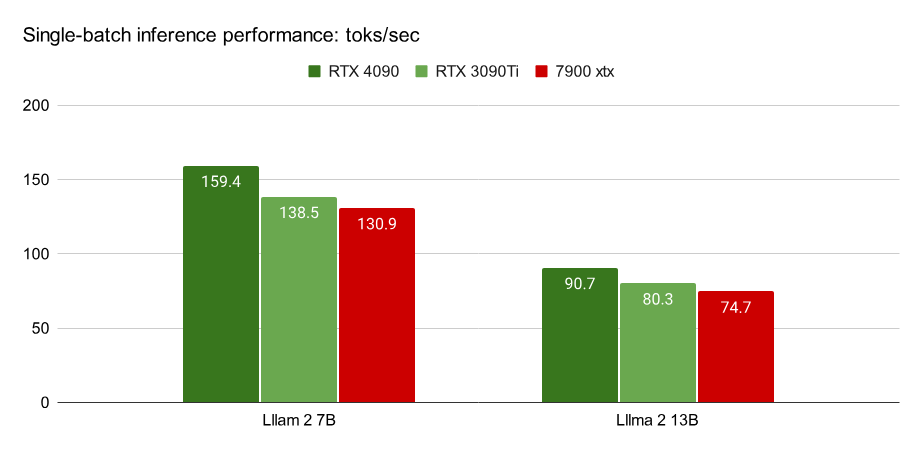
作者使用 4 bit 量化对 Llama 2 7B 和 13B 进行了性能测试。通过设置 prompt 长度为 1 个 token 并生成 512 个 token 来测量 decoding 的性能。所有结果都是在 batch size=1 的情况下测试。

AMD RX 7900 XTX 与 NVIDIA RTX 4090 和 3090 Ti 的性能对比。
基于 ROCm5.6,AMD 7900 XTX 可以达到 NVIDIA 4090 速度的 80%。
关于 CUDA 性能说明:在这里 CUDA baseline 的性能如何?据我们所知,MLC-LLM 是 CUDA 上大语言模型推理的最优解决方案。但作者相信它仍然有改进的空间,例如通过更好的 attention 算子优化。一旦这些优化在 MLC 中实现,预计 AMD 和 NVIDIA 的数据都会有所改善。
如果这些优化仅在 N 卡那里实施,将使差距从 20% 增加到 30%。因此,在查看这些数字时,作者建议放置 10% 的误差。
自行尝试
该项目提供了预构建的安装包和使用说明,以便用户在自己的设备上复现新的结果。要运行这些性能测试,请确保你的 Linux 上有安装了 ROCm 5.6 或更高版本的 AMD GPU。按照这里的说明(https://mlc.ai/mlc-llm/docs/get_started/try_out.html)安装启用了 ROCm 的预构建 MLC pacakge。
运行以下 Python 脚本,需要使用 MLC package 来复现性能数据:
from mlc_chat import ChatModule
# Create a ChatModule instance that loads from `./dist/prebuilt/Llama-2-7b-chat-hf-q4f16_1`cm = ChatModule(model="Llama-2-7b-chat-hf-q4f16_1")
# Run the benchmarksoutput = cm.benchmark_generate("Hi", generate_length=512)
print(f"Generated text:\n{output}\n")
print(f"Statistics: {cm.stats()}")
# Reset the chat module by
# cm.reset_chat()
MLC-LLM 还提供了一个命令行界面 CLI,允许用户与模型进行交互式聊天。对于 ROCm,需要从源代码构建 CLI。请按照这里的说明(https://mlc.ai/mlc-llm/docs/deploy/cli.html#option-2-build-mlc-runtime-from-source)从源代码构建 CLI。
使用统一内存在 SteamDeck 上运行 Vulkan
作者表示,还将考察更广泛的 AMD 设备,更具体地说,是搭载了 AMD APU 的 Steam Deck。虽然在 BIOS 中,ROCm 中可用的 GPU VRAM 被限制为 4GB,但 Mesa Vulkan 驱动程序具有强大的支持,允许缓冲区超越上限,使用统一内存最多可达 16GB,足以运行 4 位量化的 Llama-7B。
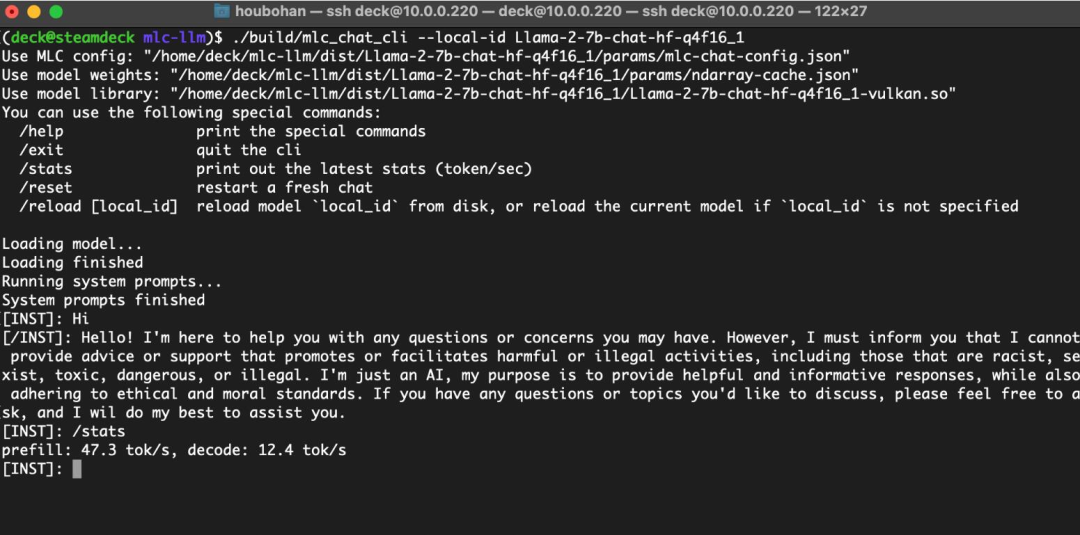
在 Steam Deck 上与大语言模型进行交互。
这些结果为支持更多不同类型的消费者提供了一些启示。
讨论和未来的方向
身处生成式 AI 的时代,硬件可用性已经成为一个迫切需要解决的问题。ML 编译可以通过在硬件后端之间提供高性能的通用部署,从而提高硬件的可用性。
鉴于本文所展现的数据,作者认为在适当的价格和可用性条件下,AMD GPU 可以开始用于 LLM 推理。
在陈天奇团队,研究目前的重点关注消费级 GPU。作者表示,根据过往经验,针对消费级 GPU 型号的 MLC 优化通常可以推广到云 GPU(例如从 RTX 4090 到 A100 和 A10g),有信心让该解决方案在云和消费级 AMD 和 NVIDIA GPU 之间具有普适性,并将在获得更多 GPU 访问权限后更新研究。与此同时,作者期待研究社区在 MLC 通用部署流程的基础上构建解决方案。
本文是通过 MLC 来支持高效通用的机器学习部署的研究的一个阶段性努力,研究人员也正积极地在以下几个方向上努力推广成果:
启用 batching 和多 GPU 支持(对服务器端推理尤为重要);
与 PyTorch 生态系统集成;
支持更多量化和模型架构;
在更多硬件后端上进行更多自动优化。
机器学习系统工程是一个持续的问题,在持续创新方面,英伟达仍然处于领先地位,作者预计随着新硬件(如 H100)以及更重要的软件演变,整个领域将发生变化。因此,关键问题不仅是现在构建正确的解决方案,还包括如何不断赶上并将机器学习工程引入新平台。在这个过程中,机器学习工程的生产力是关键。
由于基于 Python 的 ML 编译开发流程,我们可以在几小时内获得 ROCm 优化的支持。预计此次提出的新方法,在探索更多关于通用部署的想法并解决硬件可用性问题时会变得更加有用。
相关资源
该项目已经在 GitHub 上发布。有关如何尝试 MLC LLM 部署的详细指南,请参阅项目页面。MLC LLM 的源代码可在官方 GitHub 上找到。
项目页面:https://mlc.ai/mlc-llm/docs/
GitHub:https://github.com/mlc-ai/mlc-llm/
参考内容:
https://blog.mlc.ai/2023/08/09/Making-AMD-GPUs-competitive-for-LLM-inference
https://zhuanlan.zhihu.com/p/649088095
- 1USDT市值突破1100亿美元
- 210 张图揭示加密市场现状:BTC 市占率超 52%,一季度稳定币供应量上涨 14%
- 3加密市场情绪研究报告(2024.04.15-04.19):短期下跌需要做好防御措施
- 4AI 代币另一面:多数项目忙于金融利益,而非现实影响
- 5金色早报丨加密货币价值观仍在全球范围内遭受攻击 铭文某种程度算是符文的试验田
- 6上线 Runes 自研市场:如何通过OKX Web3 钱包一站式探索符文生态
- 7Bitget研究院:Runes协议上线导致BTC网络费用激增,BONK领涨Solana Meme
- 8一周融资速递 | 33家项目获投,已披露融资总额约1.26亿美元(4.15-4.21)
- 9金色早报丨Unicross开通Merlin符文跨链桥 DePIN项目累计融资超过10亿美元
 币安网
币安网 欧易OKX
欧易OKX 火币全球站
火币全球站 抹茶
抹茶 芝麻开门
芝麻开门 库币
库币 Coinbase Pro
Coinbase Pro bitFlyer
bitFlyer BitMEX
BitMEX Bitstamp
Bitstamp BTC
BTC ETH
ETH USDT
USDT BNB
BNB SOL
SOL USDC
USDC XRP
XRP DOGE
DOGE TON
TON ADA
ADA