开源且可商用,300 亿参数的 MPT-30B 大模型的成本仅为 GPT-3 的零头
AI 大模型开发公司 MosaicML 近日发布了新的可商用的开源大语言模型 MPT-30B,拥有 300 亿参数,其功能明显比前一代 MPT-7B 语言模型(70 亿参数)更强大,并且性能优于 GPT-3。

图片来源:由无界AI生成
此外,他们还发布了两个经过微调的模型:MPT-30B-Instruct 和 MPT-30B-Chat,它们构建在 MPT-30B 之上,分别擅长单轮指令跟踪和多轮对话。
MPT-30B 模型具有的特点:
- 训练时的 8k token 上下文(context)窗口
- 通过 ALiBi 支持更长的上下文
- 通过 FlashAttention 实现高效的推理 + 训练性能
- 由于其预训练数据混合,MPT-30B 系列还具有强大的编码能力。
该模型已扩展到 NVIDIA H100 上的 8k token 上下文窗口,使其成为第一个在 H100 上训练的LLM。
MPT-30B 强于 GPT-3?
MPT-30B 是商业 Apache 2.0 许可的开源基础模型,强于原始的 GPT-3,并且与 LLaMa-30B 和 Falcon-40B 等其他开源模型具有竞争力。

(上图)MPT-30B 与 GPT-3 在九项上下文学习 (ICL) 任务上的零样本准确度。 MPT-30B 在九个指标中的六个指标上优于 GPT-3。
MosaicML 用 2 个月的时间训练了 MPT-30B,使用英伟达的 H100 GPU 集群进行训练。
如下图,MPT-30B 的训练数据:

MPT-30B 通过数据混合进行预训练,从 10 个不同的开源文本语料库中收集了 1T 个预训练数据 token,并使用 EleutherAI GPT-NeoX-20B 分词器对文本进行分词,并根据上述比率进行采样。
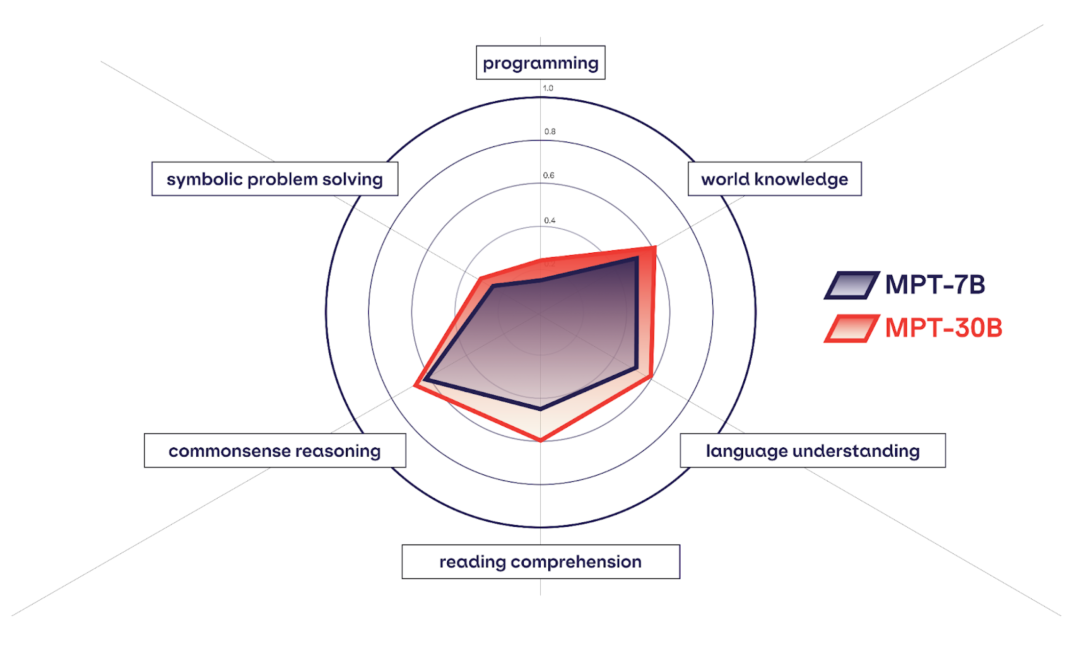
MPT-7B 与 MPT-30B 的对比
MPT-30B 训练成本
MosaicML 公司的首席执行官兼联合创始人 Naveen Rao 表示,MPT-30B 的训练成本为 70 万美元(约 502.44 万元人民币),远低于 GPT-3 等同类产品所需的数千万美元训练成本。
训练定制的 MPT-30B 模型需要多少时间和金钱? 让我们从基本模型开始。
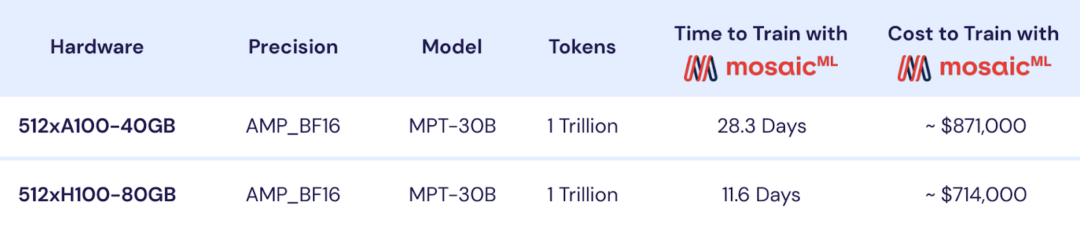
上图显示了使用 A100 或 H100 GPU 从头开始预训练 MPT-30B 的时间和成本。 借助 MosaicML 基础设施,您可以在 2 周内使用 1T token 从头开始训练您自己的自定义 MPT-30B。
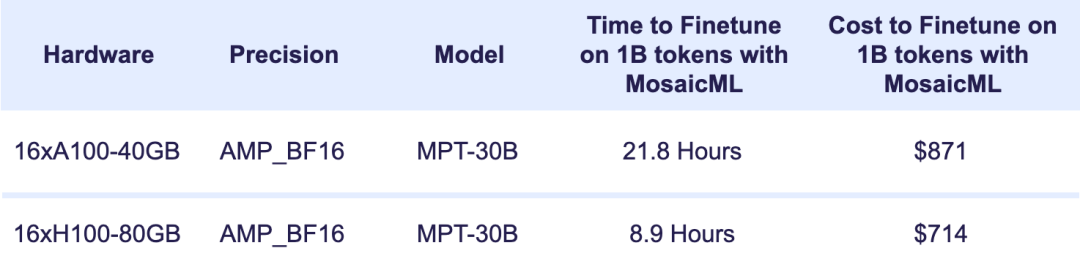
如果您不想从头训练,只想微调现有模型呢?
下图详细列出了每个 1B token 微调 MPT-30B 的时间和成本。 借助 MosaicML 基础设施,您可以对 MPT-30B 模型进行全面微调,而无需担心系统内存限制,而且只需几百美元!
MosaicML 公司表示,将模型扩展到 300 亿参数只是第一步,接下来他们将以降低成本为前提,推出体积更大、质量更高的模型。
参考资料:
 币安网
币安网 欧易OKX
欧易OKX 火币全球站
火币全球站 抹茶
抹茶 芝麻开门
芝麻开门 库币
库币 Coinbase Pro
Coinbase Pro bitFlyer
bitFlyer BitMEX
BitMEX Bitstamp
Bitstamp BTC
BTC ETH
ETH USDT
USDT BNB
BNB SOL
SOL USDC
USDC XRP
XRP TON
TON DOGE
DOGE ADA
ADA