学术向丨运用AI算法促进比特币反洗钱
译者前言:比特币等区块链应用的初衷是为实现惠普金融目的,然而,犯罪分子的使用却为它们带来了坏名声,这也凸显出了反洗钱工作的重要性,对此,MIT、IBM以及区块链分析公司Elliptic的研究者联合推出了一些检测非法区块链交易的方法,其还提供了一个包含20多万笔标记比特币交易的数据集,其中只有少数交易被归类为非法交易。
以下为论文译文:
比特币的反洗钱研究:运用图卷积网络进行金融鉴证
作者:
摘要
反洗钱(AML)监管在保障金融体系方面发挥着关键作用,但同时也使得金融机构承担了高昂的成本,并促使那些处于社会经济和国际边缘的金融被排除在外。而加密货币的出现,带来了一个有趣的悖论:假名允许罪犯隐藏于显而易见的地方,而开放的数据则赋予了调查人员更多的权力,并使法庭分析的众包成为可能。同时,学习演算法的发展也大大助推了AML工具包。在本次研讨会中,我们提供了Elliptic数据集,一个超过20万笔比特币交易及23.4万条定向支付流(边)的时间序列图,其拥有166个节点特征,包括基于非公开数据的特征。据我们所知,这是目前与加密货币相关的最大的标记交易数据集。我们分享了使用逻辑斯蒂回归(Logistic 回归)算法、随机森林(RF)算法、多层认知器演算法(MLP)以及图卷积网络(GCN)算法的变体来预测非法交易的二元分类任务结果。
其中图卷积网络(GCN)作为一种新兴的获取关系信息的方法,其具有特殊的意义。
结果表明了随机森林(RF)算法的优越性,同时也展示出了结合随机森林(RF)算法和图卷积网络(GCN)方法各自能力的可能。
最后,我们考虑到,由于现实交易图的大小及动态性方面的因素,可视化分析和解释是很难实现的,我们为此提供了一个简单的原型,其能够确定图形,并观察模型在检测非法活动方面的表现。
有了这些方法和数据集,我们希望(1)邀请反馈来支持我们正在进行的调查,(2)激励他人努力应对这一重要挑战。
关键词
图卷积网络、异常检测、金融取证、加密货币、反洗钱、可视化。
一、反洗钱(AML)与惠普金融的冲突
“贫穷的代价是昂贵的,” 这是惠普金融倡导者的共同信条。它说明了这样一个事实:那些处于社会边缘的人在进入金融体系方面受到了限制,参与的相对成本也较高。限制访问的问题(例如,注册银行账户的能力),在某种程度上是越来越严格的反洗钱(AML)法规带来的意外结果,虽然反洗钱(AML)对保护金融体系至关重要,但却对低收入者、移民和难民产生了不成比例的负面影响 [16]。而全球大约有17亿成年人处于无银行账户的状态 [7]。
相对成本较高的问题,在一定程度上也是反洗钱政策的特性造成的,该政策在货币服务业务(MSB)上强制执行较高的固定合规成本,而“低价值”客户根本不值得这些业务冒这个风险。
以全球中低收入国家的汇款为例,它们在2018年进行的汇款活动达到了5290亿美元,创下了历史新高,远远超过全球1530亿美元的援助捐款。
而目前人们发送200美元,平均的汇款费用率是昂贵的7个点,有些国家的费率甚至超过了10%。而联合国可持续发展目标是在2030年降低至3%。
尽管问题普遍存在着,反洗钱监管却不能因为负担过重的原因而被草率驳回。原因是,诸多非法产业,如贩毒集团、人口贩运和恐怖组织,在世界各地造成了众多人类悲剧。最近发生的马来西亚发展有限公司(1MDB)洗钱丑闻,夺走了马来西亚人民用于国家发展的110多亿美元纳税人资金[22],这起事件也牵连了高盛(Goldman Sachs)等组织,涉及到巨额罚款和刑事起诉。爱沙尼亚最近发生的丹斯克银行洗钱丑闻,曾是俄罗斯和阿塞拜疆约2000亿美元非法资金流入的中心,其同样给这些国家的无辜公民造成了不可估量的损失,而受其牵连的机构,如丹麦银行(danske bank)和德意志银行(deutsche bank),因此而损失数十亿美元[23]。
洗钱并不是一种无受害人的犯罪,而目前传统金融体系的方法在制止洗钱方面却做得很差。
1、1 加密货币世界的反洗钱
由比特币网络所引入的加密货币 [17] ,引发了技术与企业对支付处理兴趣的爆发。在世界各地,货币转移类创业公司开始与传统银行和诸如西联等货币服务业务(MSB)竞争。
他们专注于使用比特币和其他加密货币作为“轨道”(这一领域常用的一个术语),以实现低成本、点对点的跨境资金转移。
很多人明确指向了汇款目标,并支持惠普金融事业。
与这些企业家一起成长的,还有来自学术界的学者,以及支持更新加密货币监管政策的倡导者团体。
然而,抑制这种令人兴奋应用的,却是比特币的坏名声。
很多犯罪分子利用比特币的假名特性隐藏在人们的视线中,然后进行勒索软件攻击,并经营暗网市场,以交换非法商品和服务。
2019年5月,美国金融犯罪执法网络(FinCEN)发布了关于1970年《银行保密法》(BSA)如何适用于加密货币,这也被称为可转换虚拟货币(CVC)指南[18]。
与《银行保密法》(BSA)一致,该指南要求货币服务业务(MSB)生成衡量洗钱、恐怖主义金融和其他金融犯罪的风险评估。这些评估基于客户构成、服务地区和提供的金融产品或服务。
评估必须告知客户关系的管理层,包括实施与风险相称的控制措施。换言之,货币服务业务(MSB)不仅必须报告可疑账户,而且必须对它们采取行动(例如冻结或关闭它们)。该指南将“完善的风险评估”定义为“协助最高管理层识别并提供其个人风险状况的综合分析”。该指南强化了BSA的“了解你的客户”(KYC)要求,其要求MSB对其服务的客户有足够的了解,以便能够确定他们向机构陈述的风险水平。
对客户“足够了解”,到底是指到什么样的程度,这是合规与政策圈争论不休的话题。在实践中,其中最具挑战性的一个方面是一个隐含但有效执行的要求,即不仅要了解客户,还要了解客户的客户。在传统金融零散的数据生态系统中,这方面的合规性通常是通过MSB之间的通话来执行的。但在比特币的开放系统中,整个图形交易网络数据是公开的,尽管这是以假名和无标记的形式而存在。
为了迎接这一公开式数据带来的机遇,加密货币情报公司应运而生,它们为加密货币领域提供量身定制的反洗钱解决方案。虽然比特币的假名特性对于犯罪分子而言是一种可利用的优势,但公开数据的特性,也同样是调查人员的关键优势。
二、ELLIPTIC 数据集
Elliptic是一家加密货币情报公司,其致力于保护加密货币生态系统免受犯罪活动的影响。作为对研究社区的贡献,我们给出了Elliptic比特币交易图形网络数据集,并同意公开分享该数据集。据我们所知,它是与加密货币相关最大的标记交易数据集。
2、1 图形构造
该Elliptic数据集,将比特币交易映射到属于合法类别的真实实体(交易所、钱包提供商、矿工、合法服务等),以及非法实体(诈骗、恶意软件、恐怖组织、勒索软件、庞氏骗局等)。根据原始比特币数据,构造并标记一个图,其中节点表示交易,边缘表示比特币从一笔交易流向下一笔交易。如果发起交易的实体(即控制与特定交易输入地址相关联私钥的实体)属于合法实体,则将给定交易视为合法类别,反之则判为非法类别。重要的是,所有的功能都是使用公共信息构建的。
2.1.1 节点和边缘:有203,769笔节点交易以及234,355条定向边缘支付流。而在当前整个比特币网络,使用相同的图形表示,那么整个BTC网络大约有4.38亿个节点,以及11亿条边(截至撰写本文时的数据)。在Elliptic数据集当中,约有2%的(4545笔)交易被标记为非法,有21%的(42,019)交易被标记为合法,其余的交易没有被贴上合法或非法的标签,而是具有其他的特征。
2.1.2 特征:每个节点都关联了166个特征,其中前94个特征表示有关交易的原生信息,包括时间步长、输入/输出数、交易费、输出量以及合计数字(例如输入/输出接收(使用)的平均BTC和与输入/输出相关联的传入(传出)交易的平均数量)。其余的72个特征称为聚合特征,通过从中心节点向后/向前一跳聚合交易信息来获得(给出相同信息数据(输入/输出、交易费等)的相邻交易的最大、最小、标准差和相关系数)。
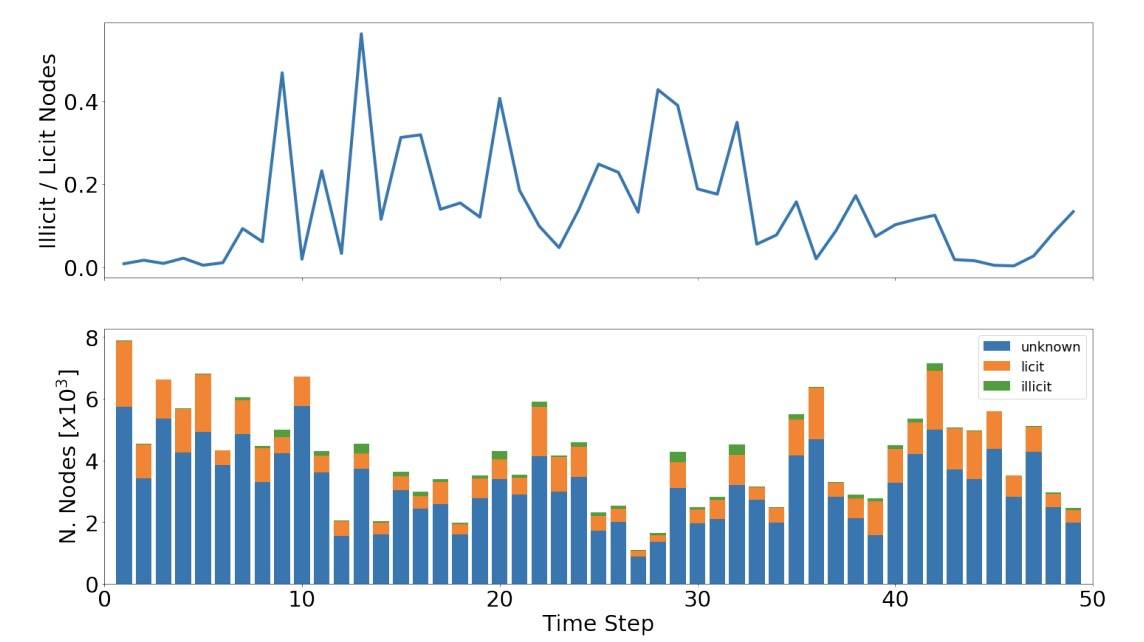
图1:(上图)数据集中不同时间步长,非法节点与合法节点的比例。(底部)节点数与时间步长
2.1.3 时间信息:时间戳与每个节点相关联,表示比特币网络确认交易时的估计时间。共有49个不同的时间步长,平均间隔约为两周。每个时间步长包含在区块链上出现的、彼此之间不到三小时的交易单个连接组件;没有连接不同时间步长的边。很明显,特定时间步长中的节点彼此关联的时间戳非常接近,因此可有效地将它们中的每一个视为时间上的即时“快照”。每个时间步长的节点数随时间的推移是相当均匀的(范围从1000到8000个节点)。见图1 。
2、2 关于特征构造的解释
合法与非法的标签过程,是通过基于启发式的推理过程来实现的。例如,较高数量的输入和相同地址的重用,通常与较高地址群集相关[10],这导致签名交易实体的匿名性降低。另一方面,将由多个地址控制的资金合并到一笔交易中,在交易成本(费用)方面提供了好处。因此,应对大量用户请求,避免使用匿名保护措施的实体可能是合法的(例如,交易所)。相反,非法活动可能倾向于使用较少输入的交易,以减少反匿名地址群集技术的影响。
此外,在为比特币交易构建特征方面还有两大挑战。第一个挑战在于比特币区块链的规模相当于200GB的压缩数据和约4亿笔已处理交易。虽然并非所有交易都包含在本研究中使用的子集中,但仍有必要访问完整的区块链,以便观察交易的完整历史。为了克服这个问题, Elliptic使用了一个高性能的all-in-memory图形引擎来计算特征。
第二个挑战来自数据的底层图结构和交易可拥有邻交易数量的异质性。在构建72个聚合特征时,异质邻域的问题是通过简单地构造邻居交易的原生特性的统计总量(最小、最大等)。一般来说,这个解决方案是次优的,因为它会带来很大的信息损失。
我们将在即将提到的关于图形深度学习方法的讨论中讨论这个问题,这些方法可以更好地解释局部图拓扑。
三、任务和方法
从高维度来讲,反洗钱分析是一项反常现象检测挑战,其目的是在不断增长的海量数据集中准确分类出少量非法交易。行业高达90%以上的假阳性率抑制了这一努力。
我们希望在不增加假阴性率的情况下降低假阳性率,也就是说,在不允许更多罪犯的情况下,识别出更多无辜者。
逻辑斯蒂回归(Logistic 回归)和随机森林(RF)算法是这项任务的基准方法。而图形深度学习也已经成为反洗钱的潜在工具[21]。
在Elliptic数据集的情况下,要对该数据执行的任务是筛选交易,以评估与给定的往来于加密货币钱包的交易关联风险。
具体来说,每一笔未标记的比特币交易都将被分类为非法或合法的。
3、1 基准方法
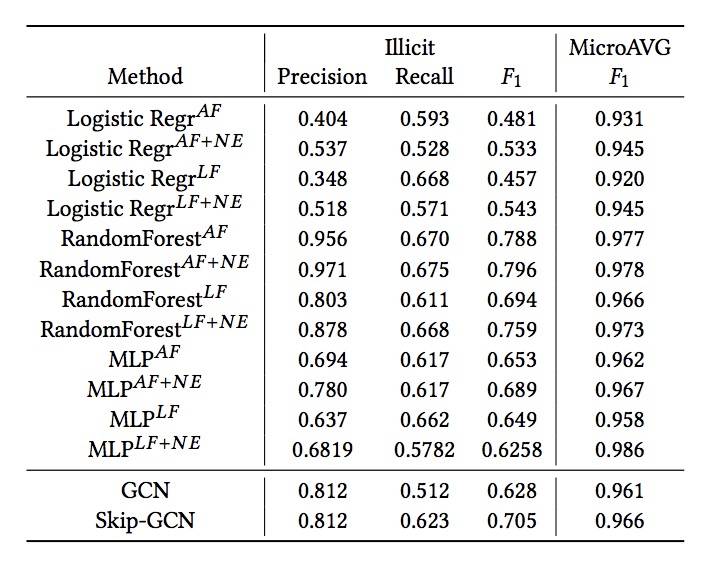
基准机器学习方法使用监督式学习中的前94个特征进行二进制分类。这些技术包括逻辑斯蒂回归(Logistic 回归)、多层认知器演算法(MLP)以及随机森林[2]算法。在MLP中,每个输入神经元接受一个数据特征,输出是一个Softmax,每个类有一个概率向量。逻辑斯蒂回归(Logistic 回归)和随机森林是用于反洗钱的两种常用方法,特别是它们各自存在的优点:随机森林用于精确性,而逻辑斯蒂回归(Logistic 回归)则用于可解释性。但是,这些方法没有利用任何图形信息。
在Elliptic数据集中,局部特征被一组包含邻域信息的72个特征增强。我们将看到这些特征的利用会改善性能。虽然这种方法显示了二元分类问题中的图结构,并且这种方法可以与标准的机器学习技术一起使用,而将纯基于特征的方法扩展到邻域之外是一个挑战。这一缺点促使人们使用图卷积网络方法。
3、2 图卷积网络(GCN)
图形结构数据深度学习,是一个迅速增长的研究课题 [3, 6, 8, 9, 14]。处理图形结构固有的组合复杂性,给实际应用带来了可扩展性挑战,而在解决这些挑战方面,研究者们已取得了重大进展 [5, 11, 24]。具体地说,我们考虑了图卷积网络(GCN)。图卷积网络(GCN)由多层图卷积组成,它类似于认知器演算法,但还使用由谱卷积驱动的邻域聚合步骤。
假设来自Elliptic数据集的比特币交易图为 G = (N, E),其中N是节点交易集,E是表示BTC流的边集。图卷积网络(GCN)的第l层采用邻接矩阵A和节点嵌入矩阵H^(l)作为输入,并使用权重矩阵 W^(l)将节点嵌入矩阵更新至H^(l+1)作为输出。数学上,我们写为:
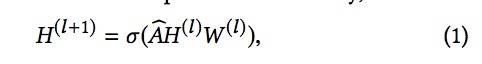
其中![]() 的定义如下:
的定义如下:
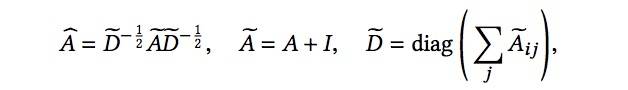
σ是除输出层外所有层的激活函数(通常为ReLU)。初始嵌入矩阵来自节点特征,例如![]() 。假设图卷积有L层,在节点分类的情况下,输出层是softmax,其中
。假设图卷积有L层,在节点分类的情况下,输出层是softmax,其中 ![]() 由预测概率组成。图卷积层与前馈层(feed forward layer)相似,差别只是前面乘的
由预测概率组成。图卷积层与前馈层(feed forward layer)相似,差别只是前面乘的![]() 。该矩阵是由图的拉普拉斯矩阵上的谱图滤波驱动的,它是拉普拉斯矩阵的一个线性函数的结果。另一方面,我们也可以将
。该矩阵是由图的拉普拉斯矩阵上的谱图滤波驱动的,它是拉普拉斯矩阵的一个线性函数的结果。另一方面,我们也可以将![]() 的乘法解释为相邻节点的转换嵌入的集合。图卷积网络(GCN)的参数是不同层l的权重矩阵
的乘法解释为相邻节点的转换嵌入的集合。图卷积网络(GCN)的参数是不同层l的权重矩阵 ![]() 。
。
一个通常使用的2层图卷积网络(GCN),可整洁地写为:
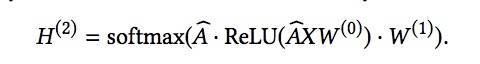
一个“skip”变量,我们发现它实际上很有用,在中间嵌入![]() 和输入节点特征X之间插入了一个skip连接,导致架构 :
和输入节点特征X之间插入了一个skip连接,导致架构 :

其中![]() 是skip连接的权重矩阵,我们称之为架构Skip-GCN。当
是skip连接的权重矩阵,我们称之为架构Skip-GCN。当![]() 是0时,Skip-GCN相当于逻辑斯蒂回归(Logistic 回归)。因此,Skip-GCN至少应和逻辑斯蒂回归(Logistic 回归)一样强大。
是0时,Skip-GCN相当于逻辑斯蒂回归(Logistic 回归)。因此,Skip-GCN至少应和逻辑斯蒂回归(Logistic 回归)一样强大。
3、3 图卷积网络(GCN)
金融数据本质上具有时间性,因为交易是有时间戳的。有理由假设存在某种动力,尽管是隐藏的,其驱动着系统的进化。如果一个预测模型是以捕捉动态的方式设计的,那么它将更加有用。这样,在给定时间段上训练的模型,可更好地推广到后续的时间步长。模型捕捉到的系统动力越好(其在进化),其所能进入的视界就越长。扩展GCN的时间模型是EvolveGCN [19],它为每个时间步长计算单独的GCN模型。然后通过递归神经网络(RNN)将这些GCN连接起来,以捕捉系统动力。
因此,未来时间步长的GCN模型是从过去的模型演变而来的,其进化捕捉了动力。
在EvolveGCN中,GCN权重被集体视为系统状态。通过使用RNN(例如GRU),模型在每次系统输入时进行更新。输入是当前时间点的图形信息。图形信息可以多种方式实例化,在EvolveGCN中,它由图中top-k个有影响的节点的嵌入来表示。
四、实验
下面是我们给出的在Elliptic数据集上获得的实验结果,我们分别对训练和测试数据进行了70:30的时间分割。也就是说,前34个时间步长用于训练模型,后15个时间步长用于测试。我们使用时间分割是因为 它反映了任务的性质。因此,GCN是在归纳环境中训练的。
我们首先使用三种标准方法来测试合法/非法预测的标准分类模型:逻辑斯蒂回归(Logistic 回归)(使用scikit learn python包 [4]中的默认参数)、随机森林(也是来自scikit-learn,具有50个估计量和50个最大特征)和多层认知器演算法(在PyTorch中实现)。
我们的MLP有一个隐藏层,其由50个神经元组成,并使用Adam优化器训练200个(epoch)时期,学习率为0.001。
我们通过使用所有166个特征(称为AF)以及仅使用局部特征(即前94个特征,称为LF)来评估这些模型。结果汇总至表1的上半部分。
表1的下半部分报告了当我们利用数据的图结构时所取得的结果。我们使用Adam优化器对GCN模型进行了1000个时期(epoch)的训练,学习率为0.001。在我们的实验中,我们使用了一个2层的GCN,然后超参数调整,我们将节点嵌入的大小设置为100。
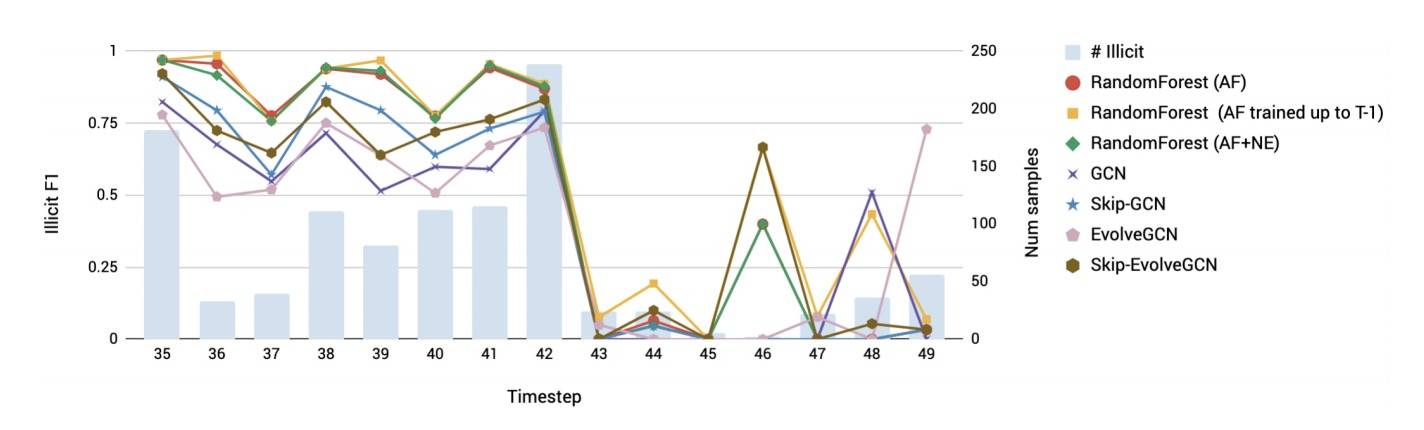
图2:测试时间跨度内的非法F1结果
表1:非法分类结果。表格上半部分显示的是没有利用图信息的结果,每个模型都显示了具有不同输入的结果:AF指所有特征,LF指局部特征,即前94个特征,而NE是指由GCN计算的节点嵌入。表的下半部分显示了使用GCN的结果。
 这个任务是一个二进制分类,两个类是不平衡的(见图1)。对于反洗钱来说,更重要的是少数分类(即非法类)。因此,我们使用加权交叉熵损失方法训练GCN模型,以提供更高的非法样本重要性。在超参数调整之后,我们为合法类和非法类选择了0.3/0.7的比率。表1显示了针对非法类的精确性、召回率(Recall)和F1分数的测试结果。为了完整起见,我们还显示了微观平均F1分数。
这个任务是一个二进制分类,两个类是不平衡的(见图1)。对于反洗钱来说,更重要的是少数分类(即非法类)。因此,我们使用加权交叉熵损失方法训练GCN模型,以提供更高的非法样本重要性。在超参数调整之后,我们为合法类和非法类选择了0.3/0.7的比率。表1显示了针对非法类的精确性、召回率(Recall)和F1分数的测试结果。为了完整起见,我们还显示了微观平均F1分数。
注意,GCN和变量Skip-GCN的性能优于逻辑斯蒂回归(Logistic 回归),这表明基于图的方法与不可知图信息方法相比是有用的。另一方面,在本示例中,输入特性已经相当丰富了,仅使用这些特性,随机森林(RF)方法就可以获得最佳的F1分数。
表1中的另一个细节来自于对所有特征(AF)和仅对94个局部特征(LF)训练方法的比较。对于所有三个被评估的模型,聚合的信息导致了更高的准确性,这表明了图结构在这个环境中的重要性。通过这一观察,我们进一步评估了增强输入特征集的方法。这个实验的目的是证明图信息对于增强交易的表示是有用的。在该设置中,我们将从GCN获得的节点嵌入与原始特征X连接起来。结果表明,增强的特征集提高了全特征(AF + N E)和局部特征(LF + N E)模型的精度。
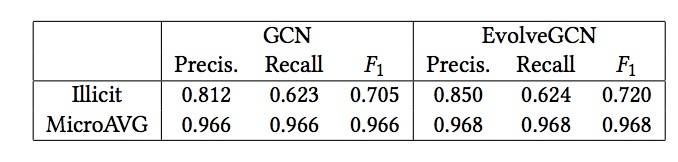
表2比较了非时态GCN和时态EvolveGCN的预测性能。结果显示EvolveGCN的性能一直优于GCN,尽管这一数据集的改进并不显著。进一步研究的一个途径,是使用其他形式的系统输入来驱动GRU内部的重复更新。
表2: GCN v.s. EvolveGCN
 黑市关闭:反洗钱的一个重要考虑因素是预测模型对新出现事件而呈现出的稳健性。这一数据集的一个有趣方面,是在数据的时间跨度内有一个黑市突然被关闭(在时间步长43)。如图2所示,此事件导致所有方法在黑市关闭后的表现都出现了不佳的情况。即使是一个随机森林模型,在每一个测试时间步长后重新训练,假设每次测试后都能获得真实的信息,也无法可靠地捕获黑市关闭后新的非法交易。对于此类事件的稳健性,是我们需要解决的重大挑战。
黑市关闭:反洗钱的一个重要考虑因素是预测模型对新出现事件而呈现出的稳健性。这一数据集的一个有趣方面,是在数据的时间跨度内有一个黑市突然被关闭(在时间步长43)。如图2所示,此事件导致所有方法在黑市关闭后的表现都出现了不佳的情况。即使是一个随机森林模型,在每一个测试时间步长后重新训练,假设每次测试后都能获得真实的信息,也无法可靠地捕获黑市关闭后新的非法交易。对于此类事件的稳健性,是我们需要解决的重大挑战。
五、讨论
我们已经看到了随机森林(RF)方法显著优于逻辑斯蒂回归(Logistic 回归)的事实,并且它也优于GCN,即使后者有图结构信息的加持。随机森林(RF)使用一种投票机制对来自多个决策树的预测结果进行集成学习,每个决策树使用数据集的子样本进行训练。与之相反,GCN则与大多数深度学习模型一样,使用逻辑斯蒂回归(Logistic 回归)作为最终输出层。因此,它可以被视为逻辑斯蒂回归(Logistic 回归)的一个重要泛化存在。
问题是:是否可以将随机森林(RF)与图神经网络方法结合使用?一个简单的想法是在运行随机森林(RF)之前,使用从GCN计算的嵌入来增加节点特征。根据先前的实验,这一想法只能起到很小的作用。文献[13]提出了另一种想法,其利用前向神经网络对决策树中的每个节点进行参数化。这种想法将随机森林(RF)和神经网络有机地结合在一起,但并没有提出如何整合图信息。一种可能的方法是用决策树的可微版本替换 GCN中的逻辑斯蒂回归(Logistic 回归)输出层,从而实现端到端的训练。
我们会在将来研究这一想法的执行情况。
六、 图形可视化
最后,为了支持分析和解释目的(对反洗钱合规是重要的),我们创建了一个名为Chronograph的可视化原型。Chronograph的目的,是通过模型的综合表示,使得人类分析师可清晰和容易地进行研究分析。
6、1 Elliptic 数据集的可视化研究
在Chronograph系统中,交易被可视化为图形上的一个节点,其边缘表示BTC从一笔交易到另一笔交易的流动。使用投影算法UMAP[15]在所有时间步长同时计算节点坐标。这种全局计算使布局在时间上具有可比性。界面顶部的时间步长滑块控件,允许用户通过仅提交选定时间步长中的节点来浏览时间。图中的非法交易被染成了红色,而合法交易则被染成了蓝色,未分类的交易则为默认的黑灰色。单击交易节点或在左侧控件中输入交易ID时,系统会可视化突出选定的交易,并以绿色突出显示所有的相邻交易(流入或流出)。在界面的左侧,用户可以看到关于不同交易类之间传输号的图表一般统计信息。
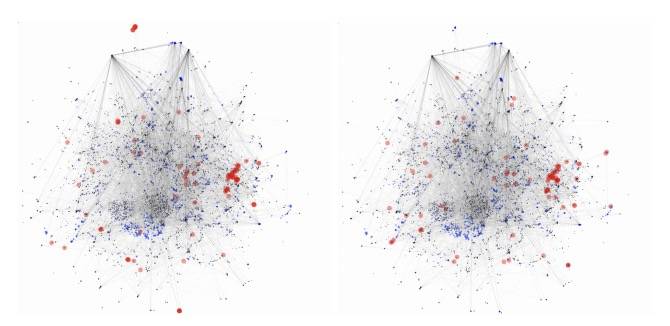
在这个简单的原型中,Chronograph使简单的探索场景能够直观地检查集群及其随时间的存在,观察明显的转移模式,或检测其他偏差,如单个异常值。作为一个更复杂的用例,我们还提高了UMAP计算输入的自由度:原始交易特性数据(图4a)以及网络最后一层的神经元激活(图4b)似乎是两个有趣的替代方案;对于一般的神经网络,Rauber等人也提出了类似的方法 [20]。结果可视化中的差异将暗示模型的特殊性,即我们假设数据之间相似性的变化,可用于解释哪些基本特征对模型是重要的。
图4显示了一个时间步长的两个可选输入的结果,原始特性数据在顶部,模型激活在底部。我们进一步使用左栏中的实际标签和右栏中的GCN预测标签对节点进行染色,然后得到4个网络可视化结果。
在基于模型的布局中,非法节点显得更为集中,这似乎是一个值得关注的特性:非法节点应该具有一些重要的特征,节点的相似性使得布局更接近。然而,由于它们并没有在一个位置完全崩溃,因此在非法节点集内存在着质的差异是很有可能的。可视化进一步揭示了模型无法检测非法节点的确切位置。如果附近地区出现多个错误预测,这可能进一步暗示该模型表现的不足。详细研究这些交易的特性,可以从新的角度启发讨论,并导致模型的进一步改进。
a)原始交易特征向量的投影

b) 最后GCN层激活的投影
图3: UMAP投影的两个可选输入,左:由输入标签着色,右:由GCN预测着色。
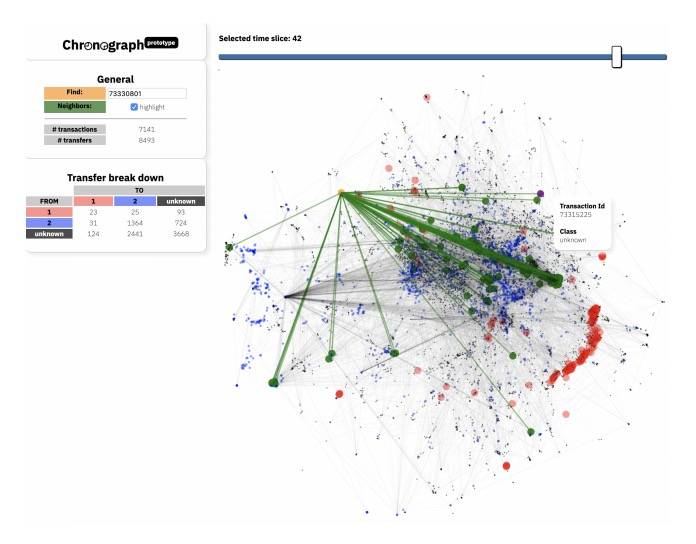
图4: Chronograph的用户界面,用户可浏览时间切片的交易数据,并观察交易模式和变化模式。其中非法交易被染成了红色。进一步的统计数据显示在左侧。
七、总结
总的来说,我们提出了一些加密货币交易鉴证法(特别是对比特币),以此打击犯罪活动。我们已向反洗钱社区提供了一个大的、带有标签的交易数据集,这类数据以前从未公开过。我们分享了早期的实验结果,使用了各种方法,包括图卷积网络,并讨论了下一步可能的算法改进。我们为这些数据的可视化提供了一个原型,并为增强人类的分析和解释能力提供了模型。最重要的是,我们希望以此激励他人应对反洗钱这一重大问题挑战,使我们的金融体系更安全、更具包容性。
致谢
这项研究工作由MIT-IBM 沃森人工智能实验室资助完成,该实验室是麻省理工学院和IBM Research联合研究计划,研究涉及的数据及领域知识由Elliptic提供。
参考文献
[1] Christopher Bishop. 2006. Pattern Recognition and Machine Learning. SpringerVerlag.
[2] Leo Breiman. 2001. Random forests. Machine learning 45, 1 (2001), 5–32.
[3] Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. 2014. Spectral Networks and Locally Connected Networks on Graphs. In ICLR.
[4] Lars Buitinck, Gilles Louppe, Mathieu Blondel, Fabian Pedregosa, Andreas Mueller, Olivier Grisel, Vlad Niculae, Peter Prettenhofer, Alexandre Gramfort, Jaques Grobler, Robert Layton, Jake VanderPlas, Arnaud Joly, Brian Holt, and Gaël Varoquaux. 2013. API design for machine learning software: experiences from the scikit-learn project. In ECML PKDD Workshop: Languages for Data Mining and Machine Learning. 108–122.
[5] Jie Chen, Tengfei Ma, and Cao Xiao. 2018. FastGCN: Fast Learning with Graph Convolutional Networks via Importance Sampling. In ICLR.
[6] Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. 2016. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. In NIPS.
[7] Demirguc-Kunt, Leora Klapper, Dorothe Singer, Sinya Ansar, and Jake Hess. 2017. The Global Findex Database 2017: Measuring Financial Inclusion and the Fintech Revolution.
[8] Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. 2017. Neural Message Passing for Quantum Chemistry. In ICML.
[9] William L. Hamilton, Rex Ying, and Jure Leskovec. 2017. Inductive Representation Learning on Large Graphs. In NIPS.
[10] Martin Harrigan and Christoph Fretter. 2016. The unreasonable effectiveness of address clustering. In 2016 Intl IEEE Conferences on Ubiquitous Intelligence & Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld). IEEE, 368–373.
[11] Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In ICLR.
[12] Knomad and World Bank Group. 2019. Migration and Remittances: Recent Developments and Outlook. Migration and Development Brief 31.
[13] Peter Kontschieder, Madalina Fiterau, Antonio Criminisi, and Samuel Rota Bulo. 2015. Deep Neural Decision Forests. In ICCV.
[14] Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard Zemel. 2016. Gated Graph Sequence Neural Networks. In ICLR.
[15] Leland McInnes, John Healy, and James Melville. 2018. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426 (2018).
[16] Daniel J. Mitchell. 2012. World Bank Study Shows How Anti-Money Laundering Rules Hurt the Poor. Forbes.
[17] Satoshi Nakamoto. 2008. Bitcoin: A peer-to-peer electronic cash system. (2008).
[18] Financial Crimes Enforcement Network. 2019. Application of FinCENâĂŹs Regulations to Certain Business Models Involving Convertible Virtual Currencies. FIN-2019-G001 (May 2019).
[19] Aldo Pareja, Giacomo Domeniconi, Jie Chen, Tengfei Ma, Toyotaro Suzumura, Hiroki Kanezashi, Tim Kaler, and Charles E. Leiserson. 2019. EvolveGCN: Evolving Graph Convolutional Networks for Dynamic Graphs. Preprint arXiv: 1902.10191.
[20] Paulo E Rauber, Samuel G Fadel, Alexandre X Falcao, and Alexandru C Telea. 2016. Visualizing the hidden activity of artificial neural networks. IEEE transactions on visualization and computer graphics 23, 1 (2016), 101–110.
[21] Mark Weber, Jie Chen, Toyotaro Suzumura, Aldo Pareja, Tengfei Ma, Hiroki Kanezashi, Tim Kaler, Charles E. Leiserson, and Tao B. Schardl. 2018. Scalable Graph Learning for Anti-Money Laundering: A First Look. CoRR abs/1812.00076 (2018). arXiv:1812.00076 http://arxiv.org/abs/1812.00076
[22] Wikipedia. [n. d.]. 1Malaysia Development Berhad scandal.
[23] Wikipedia. [n. d.]. Danske Bank money laundering scandal.
[24] Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L. Hamilton, and Jure Leskovec. 2018. Graph Convolutional Neural Networks for Web-Scale Recommender Systems. In KDD.
 币安网
币安网 欧易OKX
欧易OKX 火币全球站
火币全球站 抹茶
抹茶 芝麻开门
芝麻开门 库币
库币 Coinbase Pro
Coinbase Pro bitFlyer
bitFlyer BitMEX
BitMEX Bitstamp
Bitstamp BTC
BTC ETH
ETH USDT
USDT BNB
BNB SOL
SOL USDC
USDC XRP
XRP DOGE
DOGE TON
TON ADA
ADA